Transformer DST
Dialogue State Tracking
Dialogue State Tracking(DST)이란 Question Answering, Text-to-SQL과 같은 Semantic Parsing의 일종입니다. 이는 사용자와 시스템의 대화 내에서 사용자의 목적을 State라고 정의한 뒤, 그 State들을 정립해 나가는 과정입니다. 인공지능 스피커를 가지고 계신 분들이라면, 스피커와의 대화 속에서 인공지능이 정확하게 사용자의 요구를 파악한 뒤 그것을 행하는 전초 작업이라고 생각하시면 됩니다. 예를 들어 아래의 대화를 보시겠습니다.

사용자가 특정 이름의 호텔의 정보를 시스템에게 요구하고 있으며, 이어 택시를 불러 줄 것을 부탁하고 있습니다. 이런 대화 속에서 시스템은 자신이 수행해야 하는 Task를 정리해야 하는데 그것이 바로 DST의 Output인 State들인 것입니다. 위의 예시에서 대화가 두 파트로 나뉘어져 있는데,
- $D_1$: $S_1$ = (hotel, name, lensfield hotel), (hotel, stars, 3), (hotel, parking, yes)
- $D_2$: $S_2$ = (taxi, departure, lensfield hotel),(taxi, leaveat, 12: 30)
각 대화마다 State들이 다르게 나타나 있습니다. 이런 State들을 한 대화의 Turn마다 모아 최종 State를 나타내어 정답과 비교하는 과정이 DST의 목적입니다.
여기서 DST의 특징을 몇 가지 더 설명하자면, Multi-Domain을 안내해야 할 것 같습니다. DST가 난이도가 꽤 높아 성능 지표가 아직 60%대로 안정적으로 나타나지 않고 있는 이유는 사람과 시스템의 대화가 다양하게, 즉 Multi한 Domain내에서 이루어지기 때문입니다. 해당하는 데이터셋은 Multi-WOZ Dataset이며, 이는 7개의 다양한 도메인이 여러 조합으로 섞여 있는 모습을 띄고 있습니다.
DST에 대한 자세한 내용은 제가 설명하는 것보다 연구실의 DST의 대가인, 이유경 박사과정의 세미나 영상 및 글을 보시는 것이 좋을 것 같으며, 저는 본 포스트의 진 목적인 Transformer-DST에 대한 논문 리뷰를 진행하도록 하겠습니다. 이유경님의 링크는 하단에 첨부하도록 하겠습니다.
Transformer DST
기존의 SOTA를 찍고 있던 DST 모델들의 공통적인 특징은 두 가지의 절차를 순서대로 진행한다는 점입니다. 이는 State Operation Prediction(SOP)와 Value Generation(VG)가 있으며 두 과정은 아래와 같습니다.
- SOP: 대화 내에서 어떤 (Domain, Slot) 쌍이 업데이트 되어야 하는지 파악합니다. 사실 이런 특성은 보편화가 된지 얼마 안되었으며 SOM-DST라는 모델에서 처음 주장이 되었으며, SOP에서 본 목적을 달성합니다. 이 과정에서 BERT를 인코더로 활용합니다.
- VG: SOP를 통해 얻어낸 결과물인 ‘어떤 쌍을 업데이트 해야 하는가?’에 대하여 해당하는 Value를 생성해냅니다. 이 과정에서 BERT output을 RNN 기반 디코더로 해결합니다.
그런데 여기서 문제는 이 두 부분이 독립적으로 훈련이 되게 때문에, 서로에게 영향을 주지 못한다는 겁니다. 즉, SOP에서는 BERT 인코더만이 훈련이 되고, VG는 RNN 디코더에서만 훈련이 되게 됩니다. 따라서 Transformer DST는 이 부분을 지적하며, Transformer를 활용한다면 두 개의 독립적인 모듈을 하나의 과정으로 훈련시켜 DST의 성능을 향상시킬 수 있다고 주장하고 있습니다.
BERT와 다르게 Transformer의 본래의 목적은 Generation이었습니다. 따라서 DST의 Value 역시 쉽게 생성해낼 수 있을 것 같지만, 기존의 포맷을 그대로 사용하는 것은 성능의 저하가 나타났다고 합니다. 이는 DST가 기존의 생성 Task라고 부르기에는 입력의 형태가 많이 달라서 그런게 아닌가 싶습니다. 좀 더 자세하게 논문에서는 다음과 같이 말합니다.
Translation은 입력 문장의 토큰들을 인코더를 통해 번역해 나가지만, DST는 입력 값의 극히 일부분만을 통해 생성해나갑니다. 따라서, Transformer의 원래 목적인 번역이 입력 문장의 전체 범위를 학습하는 반면, DST는 그렇지 않기 때문에 발생하는 현상이 아닐까 싶습니다.
따라서 Transformer DST는 생성해내야 하는 Value와 연관이 있는 인코더의 Hidden State를 재사용합니다. 의미가 좀 불분명할 수 있지만 본격적으로 모델을 설명하면서 해결해보도록 하겠습니다.
Method
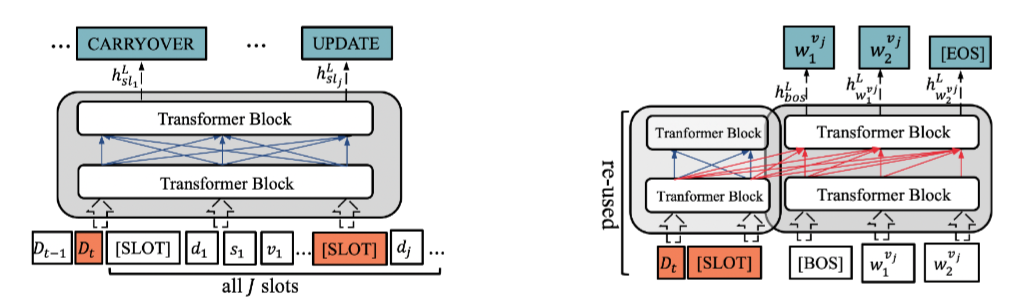
DST의 형태를 기본적으로 아시고, Transformer를 알고 계신다면 Transformer DST의 구조는 매우 쉽습니다. 따라서 간략하게만 서술하도록 하겠습니다.
State Operation Prediction (SOP)
Encoder의 입력 값은 $D_{t-1}, D_t, S_{t-1}$ 입니다. D는 Dialogue이며, S는 State 그리고 아래 첨자 t는 시점을 말합니다. 따라서 t 시점에서의 인코딩은 t-1 시점의 대화와 state가 입력값이 되는 것입니다. 3개의 입력 값을 Concat하여 BERT로 나타나는 Transformer Encoder에 넣어주게 되며, 그림에서 [SLOT]으로 나타나있는 부분은 각 Domain-State-Value로 나타나있는 State들에 대한 표상으로 앞에 추가해주는 요소입니다. 입력 값이 구성되었다면, 그 이후의 과정은 Transformer의 과정을 따릅니다.
인코더를 통해 각 요소의 Hidden Representation이 나타날텐데, 여기서 [SLOT]의 역할을 이해하실 수 있습니다. [SLOT]이 State들의 요약이라고 말씀드렸는데, 즉 [SLOT]들에 대한 Operation Prediction을 하게 되면, 해당 [SLOT]을 어떻게 대해야 할 지 결정할 수 있습니다. Operation Prediction의 값은 다음과 같습니다.
- CARRY-OVER: Slot Value를 변경하지 않는다.
- DELETE: Value를 NULL로 바꾼다.
- DONT CARE: Value를 DONT CARE로 바꾼다.
- UPDATE: 디코더가 새로운 값을 생성해낸다.
Slot Value Generation (VG)
이어서 Transformer DST의 디코더를 통해 각 Slot의 값을 생성해나가는 과정을 설명하도록 하겠습니다. 이는 Transformer의 Decoding 과정과 매우 유사하기에 Encoder의 Hidden Representation을 활용합니다. 하지만 앞에서 설명드렸다시피, Transformer를 그대로 사용하는 것, 즉 인코더의 모든 값들을 활용하는 것은 성능의 저하를 가져오기 때문에 UPDATE로 State Operation이 할당된 SLOT에 대해서만 Encoder의 값을 사용합니다. 논문에서는 이를 ‘Re-use’라고 표현합니다.
훈련 시에는 Teacher Forcing으로 값을 생성해내며, 생성된 Slot 값의 auto-regressive loss를 적용합니다.
Experiments
실험에 사용되는 데이터셋은 MultiWOZ 2.0과 MultiWOZ 2.1이며, 다양한 도메인을 포함하고 있는 데이터셋입니다. 논문에서는 정말 많은 Baseline Model들과의 비교를 진행하고 있으며, MultiWOZ 2.0, 2.1에서 모두 SOTA 성능을 달성하고 있습니다.
실험 결과
DST의 성능 측정 지표는 Joint Goal Accuracy를 사용합니다. 이는 각 턴의 정답 slot value와 생성해낸 value가 모두 일치할 때 +1를 하게 됩니다. 이 부분에서 확실히 완벽한 예측을 하지 않으면 성능이 높게 나타나지 않게 되어, DST의 SOTA 성능이 60%를 잘 넘지 못하게 되는 것이라 생각합니다.
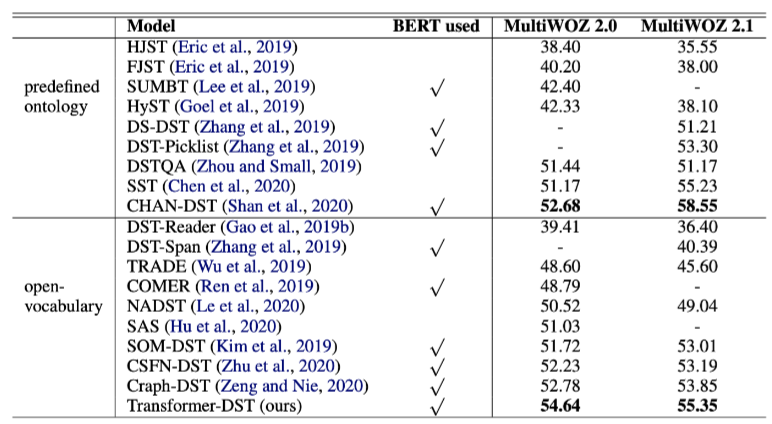
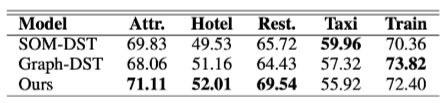
다른 모든 모델들에 비해 Transformer DST가 높은 성능을 달성하고 있는 것을 보이며, 논문에서는 SOM-DST와 SOM-DST에 기반하여 Graph 정보를 추가한 Graph-DST와의 비교를 진행하는데, 이 때 각 도메인별 성능을 비교합니다. 즉, Transformer-DST는 Taxi와 Train에서는 SOTA 성능을 달성하지 못하고 있는데, 이는 Taxi와 Train이 다른 Domain들과 함께 등장하는 비율이 높아 co-occurrence 정보를 추가하는 Graph-DST보다 성능이 낮다고 예측하고 있습니다.
다음으론 실험의 의미에 대해서 파악해보겠습니다.
How does joint optimization help the model to converge fast?
다른 모델들과 다르게 SOM-DST는 SOP와 VG를 독립적으로 시행하는 것이 아니라 종속적으로 합니다. 이것이 단순하게 봤을 때 훈련을 더 간단하고 효율적으로 하기 때문에 최적의 결과를 뽑아낼 수 있다고 생각할 수 있는데 과연 정말로 그럴까요?

위의 그림은 Epoch 별로 성능 지표인 JGA에 대한 SOM-DST와 Transformer-DST의 비교입니다. 확실히 epoch이 증가할수록 Transformer DST는 빠르게 성능이 향상하고 수렴하는 시점도 SOM-DST보다 늦습니다. 또한 Test의 성능이 SOM-DST보다 높고 일정한 것을 살펴볼 수 있습니다. 즉, SOM-DST는 과적합의 문제를 겪지만 Transformer DST는 그 비중이 낮다고 할 수 있습니다.
How is the model efficiency?
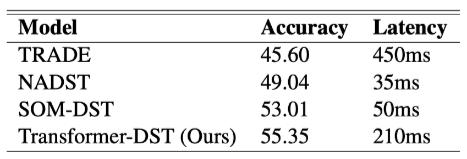
다음으로는 모델이 얼마나 효율적인지에 대한 답을 해보겠습니다. 확실히 TRADE 같은 경우에는 SOP를 진행하지 않고 모든 Slot에 대한 Value 생성을 진행하기 때문에 Latency가 매우 높습니다. Transformer-DST가 그 뒤를 잇고 있지만, 논문에서도 역시 기술하고 있는 부분은 DST라는 것이 빠르게 사용자의 요구사항을 파악하는 것이 중요한 부분이기 때문에 현재로써는 정확도가 높아도 SOM-DST를 사용하는 것이 더 좋을 것이라고 추천하고 있습니다. 그럼 더 빠르고 좋은 최상의 GPU를 사용하면 달라질까 싶지만 그 비용 대비 성능 향상이 좋지 않았다고 합니다.
What is the impact of re-using different parts of the model input
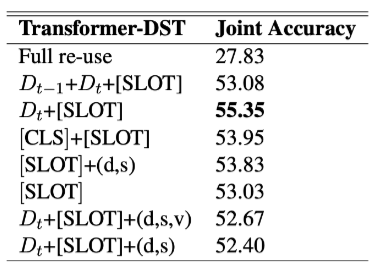
위에서 계속 언급해왔던 Transformer 입력값 형태인 전체 문장을 모두 사용하는 것이 성능이 낮은 부분에 대하여 Transformer DST는 현재 생성해야 하는 State와 대응하는 Dialogue만을 사용하여 성능을 개선했다고 했습니다. 이에 대하여 Ablation Study를 진행하여 어떤 입력값을 사용하는 것이 성능이 가장 좋을 지에 대한 성능 평가는 위의 그림과 같으며 다양한 조합으로 실험했을 때 모델에서 제시하는 형태가 최상의 성능을 나타내는 것을 볼 수 있습니다.
추석을 맞이하여, DST에 대한 글을 적어보았습니다. 확실히 해당 분야는 어려우며 이 분야의 높은 성능을 달성할 수 있는 아이디어가 하늘에서 떨어지는 날만을 꿈꾸고 있습니다…라고 말했더니 연구실 동료가 ‘사실 그러려면 논문을 많이 일거야 한다’고 넌지시 말하여, 오늘도 벌레벌레개벌레의 좌절이 시작되었습니다… 긴 글 읽어주셔서 감사합니다.
참고 자료