Attention is not not Explanation
Attention is not explanation 오타가 아니라, 진짜 not not 입니다.
본 논문은 Attention is not Explanation (이하 not Ex)논문이 발표된 후, Attention이 설명력이 없다는 논리를 반박하는 주장을 합니다.
Attention is not Explanation에서의 주요 주장 두 가지는,
- Attention이 다른 Feature Importance와 Correlation이 적다.
즉, Attention은 모델을 설명하기 위한 요소를 나타내는 것이 아닌 다른 요소를 표현한다. - 하나의 결과를 예측하기 위한 Attention에 대하여 동일한 결과를 도출하는, 다른 Adversarial Attention을 구성할 수 있기 때문에 ‘Faithful Explanation’이 되지 못한다.
Not Not Ex는 Not Ex의 주장에 대하여, 절대적으로 부정하지는 않고 예의를 차리면서, ‘너희들 주장이 부분적으로 맞는데 이 부분은 틀리지 않았을까?’라는 조심스러운 Stance를 취하고 있습니다. 먼저 첫번째 주장에 대해선 설명력의 Consistency를 파악하려는 시도였기에 인정하고 있지만, 두 번째 주장은 동의하지 않고 있습니다.
두번째 주장에서 Adversarial Attention을 구성하는 방법은, Attention을 훈련을 통해 구해낸 다음 Freeze하여, Attention을 Random하게 Permutation하는 방식을 취하는데 해당 방식이 Model Based가 아니기에 지나치게 수작업으로 수정한 느낌이 든다는 것입니다.
주요 주장
즉, 본 논문은 Adversarial 또는 Counterfactual attention weight을 더 정교한 방식으로 구해내어 Attention이 설명력을 가질 수도 있음을 보입니다. Jain and Wallace 가 고안한 분포가 옳지 않은 이유는 아래와 같습니다.
- Attention Distribution is not a Primitive
Jain and Wallace는 Attention을 모델에 독립적인 존재로 간주하고, 그에 대한 Permutation을 진행하여 결과의 변화를 살펴보았습니다. 하지만 해당 방식은 옳지 않다고 하는데 그 이유는 Attention은 모델의 종속적인 존재이기 때문에 독립적으로 분해해서 활용할 수 없으며, 모델의 다른 부분은 고정한 채 Attention만을 수정하는 것은 모델과 Attention의 관계를 반영하지 못하게 됩니다. 따라서, Adversarial Attention을 만드는 방식이 단순 Permutation이 아니라 모델을 기반으로 구성되어야 한다는 것입니다. - Existence does not Entail Exclusivity
Not Ex에서 진행한 실험은 자유도가 너무 높다고 합니다. 사실 자유도에 대해서는 명확하게 잘 모르지만, Attention에 대한 조정을 하더라도 같은 결과 값이 나오는 것이 크게 이상하지 않다고 하는데 그 이유는 LSTM의 마지막 Layer에서 모든 Token들이 취합되기 때문입니다. 즉, Aggregation을 진행할 때 Binary Classification이기 때문에 Attention이 크게 변하더라도 같은 결과를 낼 수 있는 여지가 매우 크다고 합니다. - 즉, Jain and Wallace의 Adversarial distribution은 옳은 방식으로 구성된 것이 아니며, Adversarial Model의 존재를 보여야 함을 서술합니다.
Attention이 애초에 쓸모가 있는가를 검증
Not Ex에서는 모든 데이터셋에 대하여 Adversarial을 생성합니다. 하지만 만약에 특정 데이터셋에서 Attention이 있으나 마나한다면, 즉 효용성이 없다면 굳이 Explanation인가를 검증할 필요가 없게 됩니다. 따라서, 기존 Attention을 Uniform하게 변형했을 때 성능 변화가 적은 데이터셋은 실험 대상에서 제외하고, 변화가 존재하는 데이터셋에 대하여 Adversarial을 생성하는 것을 목적으로 첫번째 실험을 진행합니다.
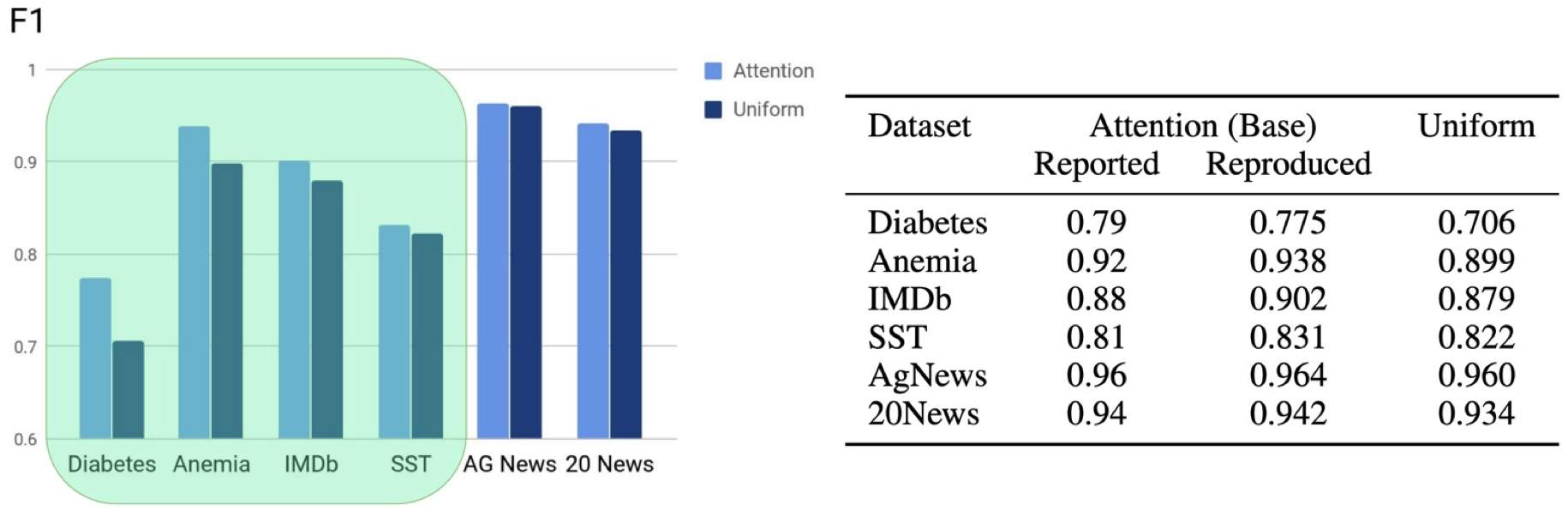
실험 결과, AG News / 20 News 데이터셋에서는 Attention을 Uniform하게 대체했을 때, 성능의 큰 차이점이 존재하지 않다고 나타납니다. SST 역시 큰 차이점이 존재하지는 않지만, 다른 세 데이터셋에 대한 비교군으로서 실험 대상에 포함시켰습니다.
Model 결과에 대한 Variance 검증
애초에 Model의 Attention이 Adversarial Attention이 아니더라도 불안정하여 변화가 쉽다면 Adversarial의 존재가 딱히 신기하지 않을 것입니다. 따라서 먼저 Model의 Random Seed를 변화시켜가면서 나타나는 Attention 분포의 변화를 살펴봤을 때, 차이가 크지 않음을 보여 Normal 상태를 규정한 뒤, Adversarial의 존재를 보여줘야 의미가 커지게 됩니다.
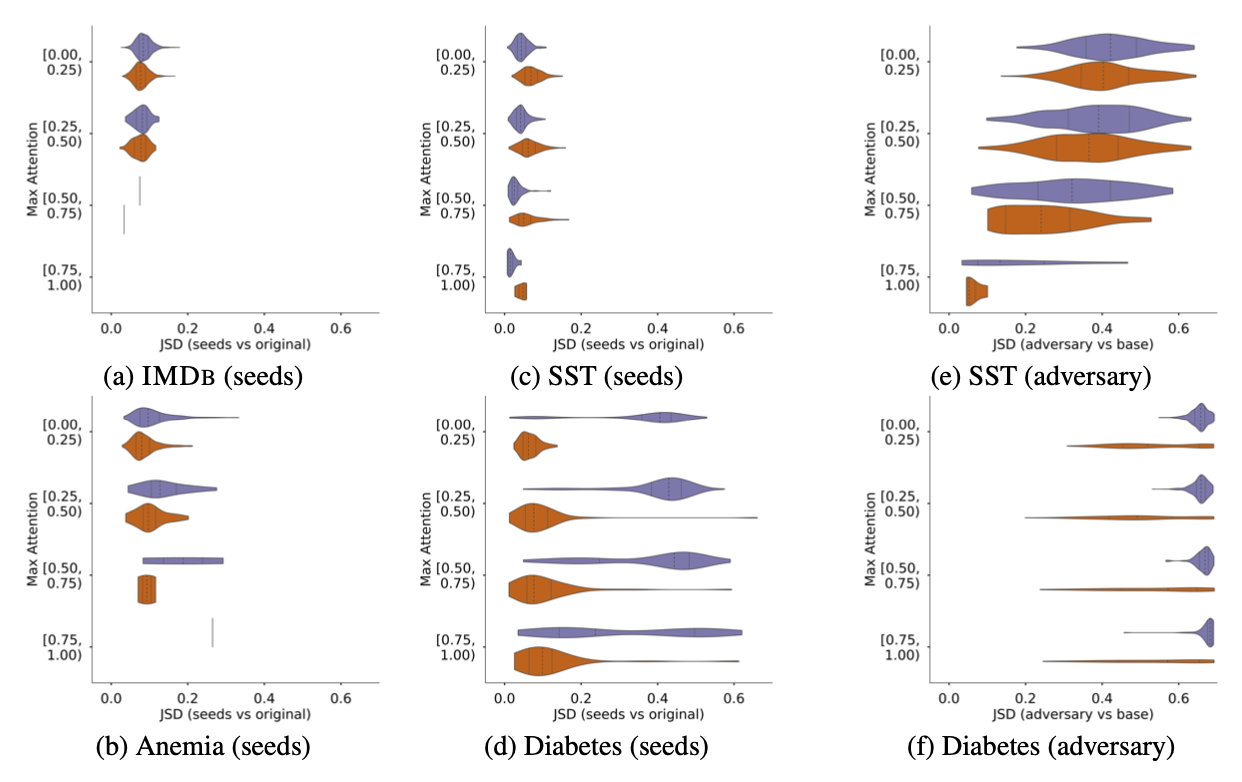
실험 결과, a,b,c,d 데이터셋에 대해서는 Seed를 변화시켰을 때, 분포 차이를 측정하는 JSD가 크게 변하지 않는 반면, Not Ex 방식으로 생성한 Adversarial이 큰 JSD를 나타내는 것을 볼 수가 있습니다.
LSTM의 상호 종속성을 ‘배제’한다. 오로지 Attention Power만 본다!
LSTM은 Token 간의 종속성을 기반으로 Hidden Representation을 계산합니다. 즉, Attention의 독단적인 Power를 보기 힘든데, 이것을 해소하기 위하여 LSTM 대신 MLP를 활용한 모델을 구성합니다.
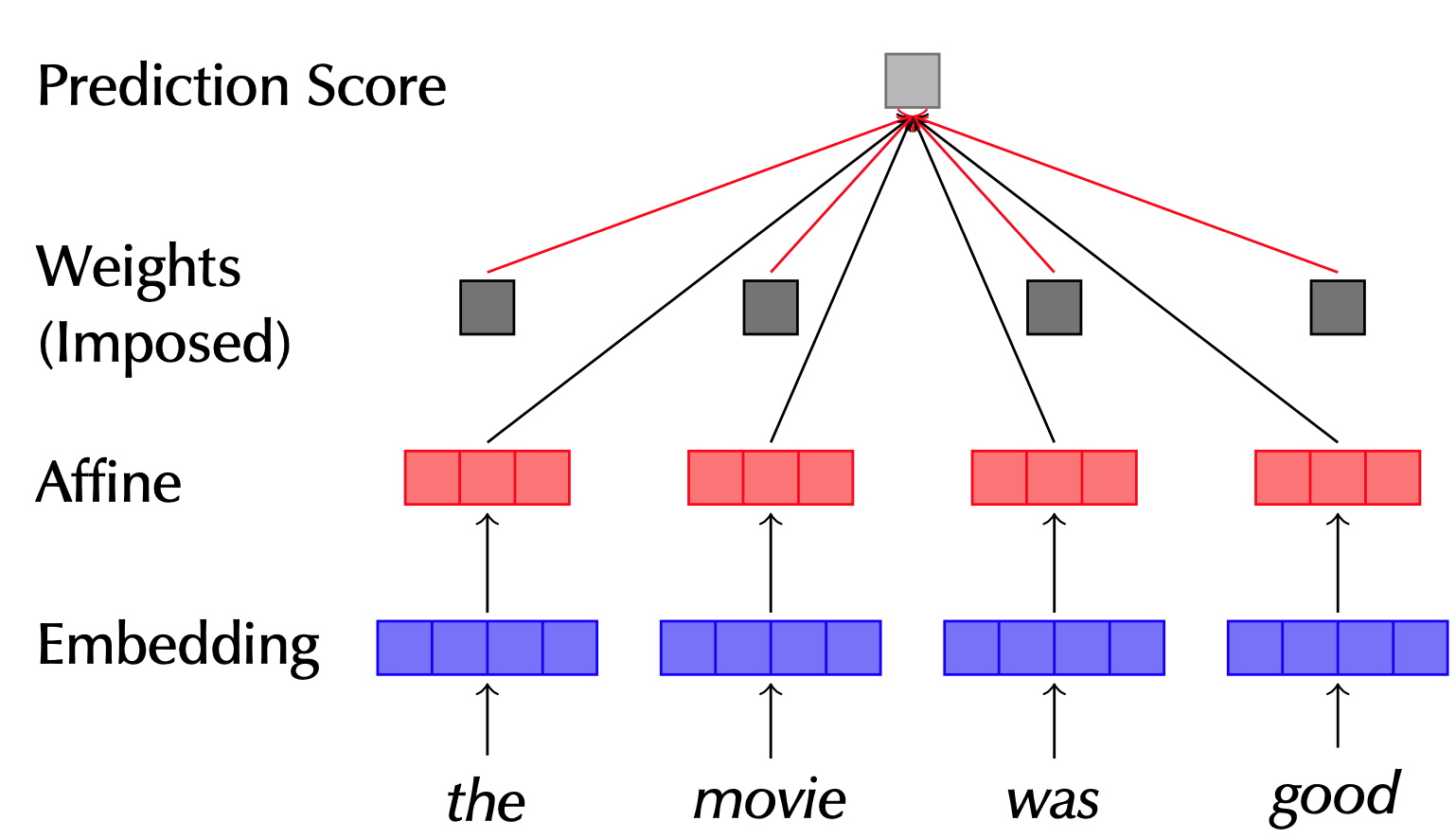
즉, 실험 대상인 모델이 4가지로 구성이 되는데
- Uniform
MLP를 사용하는 모델에 대하여 Attention을 Uniform하게 구성. 즉, Attention이 없는 것과 동일 - Trained MLP
MLP 가중치를 고정하지 않은 채로, attention을 자체 학습 - Base LSTM
MLP에 LSTM을 통해 얻은 Attention을 사용하여 계산 Trained MLP와 Base LSTM이 이름때문에 좀 많이 헷갈려서 많은 시간을 바라만 봤던 것 같습니다. 맥락을 좀 더 생각해봤을 때, Trained MLP는 MLP를 통해 자신이 얼마나 활용되어야 할지 Attention을 구하게 되는데, 이는 다른 Token들에 대한 Context를 살피지 않은 채로 계산하는 Attention입니다. 이는 확실히 Context를 반영한 Attention보다는 성능이 낮아야 실험의 의미가 있으므로 Base LSTM은 LSTM Attention을 베이스로 예측을 한 모델이라고 할 수 있겠습니다. 아래에 표에서 Base LSTM에 볼드체로 강조를 한 부분에서 맥락을 캐치할 수 있었습니다. - Adversary
훈련 알고리즘을 통해 Adversarial을 생성하여 훈련을 진행
실험 결과
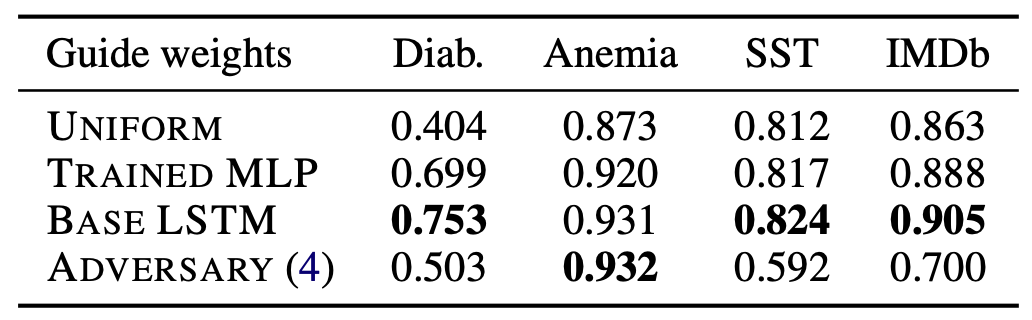
- Base LSTM, 즉 Attention을 활용하는 것이 다른 모델들보다 좋다.
- Trained MLP 같은 경우 Token 간의 상호관계를 반영하지 않고 자기 자신의 중요도를 판단하는 모델인데, 해당 모델의 성능이 덜하다.
Adversary 훈련 방법
위에서 Attention이 의미가 있다는 것을 보이고, 설명력의 가치가 있다는 것을 나타냈으므로 이제는 본격적으로 올바른 Adversarial Attention을 생성하는 훈련 방법을 제시합니다. Adversarial을 전혀 새롭게 구성하는 해당 방식은 이전 방식보다 자유도가 크게 감소하기 때문에, 진정한 Adversarial이라고 볼 수 있습니다.
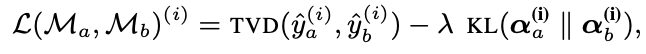
먼저 기본 모델인 $M_b$ 가 있을 때, 해당 모델에 Input을 넣었을 때 나타나는 output $y$가 있을 것입니다. 위의 목적식의 의미는 $M_b$의 Output 분포를 최소한으로 변화시키면서, 우항인 KL Divergence를 크게하는 것인데 $\alpha$가 attention distribution이 되게 됩니다. 즉, 위의 목적식을 만족하는 $M_a$를 수립하는 것이 훈련 목적이며, 해당 모델을 통해 도출하는 Attention이 진정한 Adversarial Attention이라고 할 수 있습니다. $\lambda$는 trade-off를 조절하는 파라미터로서, 낮은 TVD (예측의 차이가 적음)와 높은 JSD (더 Diverse한 Attention 분포)를 조절합니다.
사실 이렇게 목적식을 수립하게 되면, Train에서는 성능이 잘 나온다 하더라도, Test에서 Attention이 Diverse한 것을 보기 이전에 Prediction 성능이 좋지 않게 나타날 수도 있습니다. 애초에 성능이 보장되어야 Attention을 살펴보는게 의미가 있기에 중요한 부분입니다. 따라서 JSD가 최소 0.4가 벌어진 경우에 대하여 Test 성능을 살펴보는 것이 의미가 있다고 할 수 있는데 결과를 살펴보게 되면 Test 성능이 유지되는 것을 볼 수 있습니다.
Adversarial Training을 거친 이후, 각 데이터셋에 대해 성능을 평가하게 되면, 이전 Jain and Wallace의 실험과는 다르게 성능이 매우 낮아지는 것을 볼 수 있습니다. (바로 위 표) 이는 Adversarial Attention을 엄밀한 정의로 구성하게 된다면, 같은 예측을 할 수 없게 된다는 것을 시사합니다.
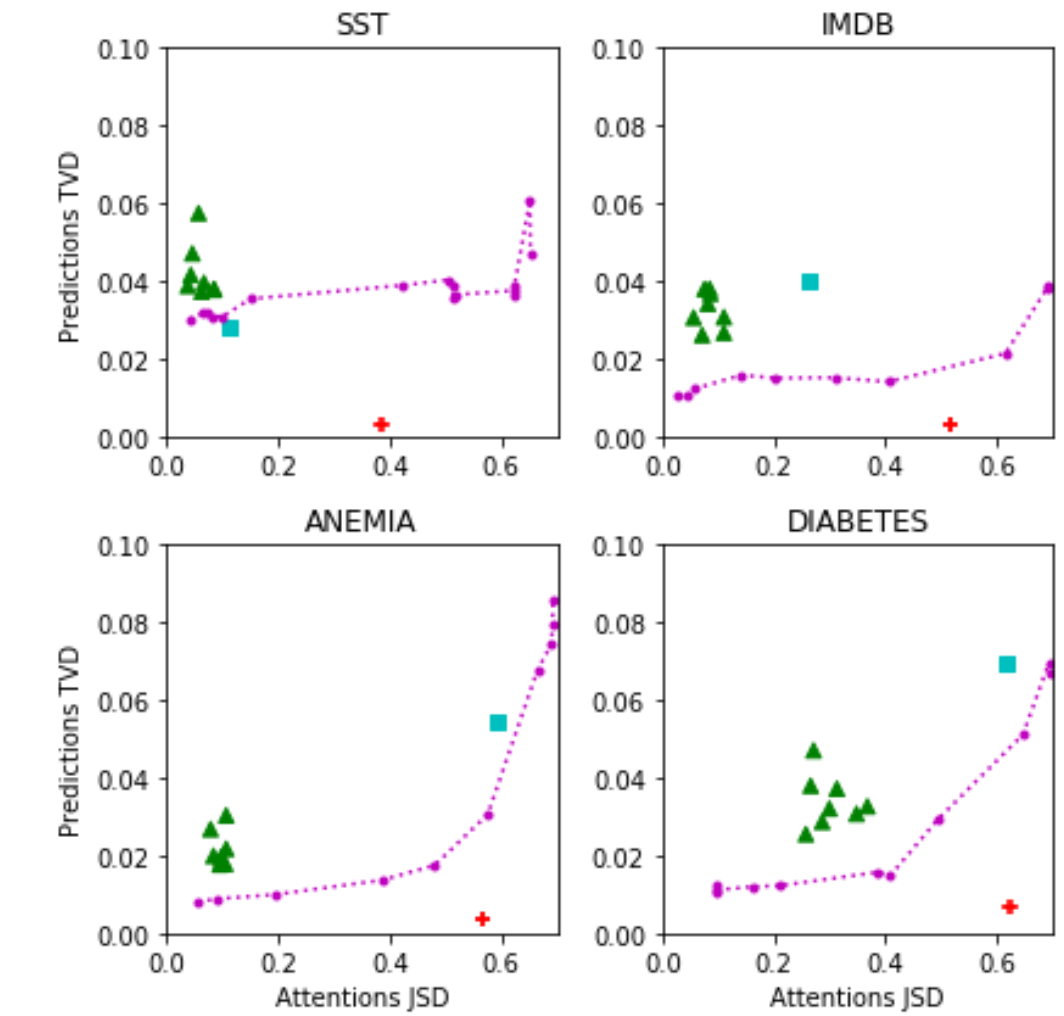
개인적으로 본 논문에서 가장 마음에 드는 결과는 위의 그림입니다. 위의 그림은 앞에서 언급한 $\lambda$ 파라미터를 변경해가면서 TVD와 JSD의 변화를 살펴보는 그림인데, 각 요소 (점, 선)의 색깔마다 의미하는 바가 있습니다.
- 초록 삼각형: Random Seed
Random Seed가 달라지지만 TVD, 즉 Prediction은 크게 변하지 않고, Attention JSD도 변하지 않습니다. 즉, Random Seed에 따라 Robust한 Attention이 구성된다고 할 수 있습니다. - 하늘색 사각형: Uniform Attention Distribution
- 보라색 점선: Adversarial Attention
Adversarial Attention의 TVD와 JSD의 변화를 살펴보게 되면, SST를 제외한 나머지 데이터셋에서 TVD가 증가하면, JSD도 함께 증가하는 양상을 볼 수 있습니다. 즉, 같은 결과를 내지만 다른 Attention을 제시하는 Adversarial Attention은 생성하는 것이 어렵다는 뜻입니다. - 빨간색 +: Jain and Wallace 방식의 Attention
해당 점은 본 논문에서 제시한 Adversarial Model의 패턴을 따르지 않습니다. 즉 매우 Manual하게, 또는 Cherry Picking하여 생성된 결과물이라고 할 수 있습니다.
결론

본 포스트를 작성함에 있어, 많은 부분을 논문과 EMNLP 발표자료에서 그림을 참고하여 구성하였으며 특히 그들의 발표가 꽤 좋은 발표였기에 이해에 도움을 많이 받았습니다.
위의 그림도 발표자료에서 가져온 그림인데, 해당 그림을 기준으로 논문을 요약해보자면, Attention은 Explanation으로서의 역할을 한다는 것을 직접적으로 증명했다기보다, Jain and Wallace의 주장에 대하여 반박을 하는 등의 간접적인 방법 사용
- 다른 Feature Importance와의 상관이 낮아서 Attention이 Explanation이 아니다라는 부분은 ‘Consistency’ 관점에서 동의
- ‘Faithful Explanation’에 해당하는 Adversarial Attention이 지나치게 자유도가 높으므로 조절하여 Adversarial을 생성해야 한다.
- Necessary: Attention 꼭 필요한가?
Attention을 Uniform으로 고정했을 때 성능 하락하는 Task를 선택 - Hard to Manipulate: Adversarial Attention을 생성하는 것이 은근히 까다롭다.
즉, Explanation이 쉽게 흔들리지 않는 존재이다. - Use Attention as Guides: Attention을 사용하지 않은 모델에 Attention을 적용하면 성능이 향상되어서, 중요한 존재이며 목적에 맞는 학습을 돕는다.
Attention is not Explanation의 반대급부인 Attention is not not Explanation에 대한 설명을 마치겠습니다. 이상 전달 끝.