Attention Flow
본 포스트는 Attention Flow라는 개념을 처음으로 제안한 논문을 리뷰해보겠습니다. Attention Flow는 Attention을 포함하는 많은 모델들에 대하여 사후 처리를 통해 Attention의 설명력 효과를 증강시키는 개념입니다. 사실 많은 연구들에서 자신들의 의중과 결부하는 모델이 구성되었음을 증명하기 위하여 Attention Plot을 보여주곤 하는데, 실제로 Attention Matrix를 그려보게 되면 예상과 다른 결과가 나타나곤 합니다. 가령, 문장의 토큰을 생성하는 Generation Task의 경우, 토큰과 직접적인 연관성이 있는 토큰에 Attention 이 적용되는 대신, 쉼표나
이에 반해 Attention Flow 또는 논문에서 제안하는 Attention Rollout을 사용하게 되면, 다른 설명력 수단인 Gradient 또는 Leave-one-out (Blank-out) 방식과 Attention에 비해 더 높은 상관성을 갖게 됩니다. 즉, 설명력으로서의 역할이 강화되었다는 뜻입니다. 지금까지 Attention의 설명력을 평가하는 논문들에서는 아쉽게도 이런 현상이 있다 정도로만 설명하고, 그래서 어떻게 극복해야 하는 지에 대한 제안은 하지 않습니다. 하지만 본 논문은 그것을 시도했기에 의의가 크다고 생각합니다.
다음의 링크는 본 논문과 논문 작성자들의 블로그입니다. 내용 이해에 더 큰 도움이 될 것이기에 첨부합니다.
- https://arxiv.org/abs/2005.00928
- https://samiraabnar.github.io/articles/2020-04/attention_flow
- https://github.com/samiraabnar/attention_flow
Setups and Problem Statement
Verb Number Prediction Task
본 논문의 Task로는 문장에 사용되는 동사의 단 / 복수형을 맞추는 문제로서, 동사가 나오기 전까지의 문장을 입력값으로 제시한 뒤에 동사의 수를 맞추는 것입니다. 예시 문장은 다음과 같습니다.
[CLS] [BOS] the key to the cabinets $\rightarrow$ (is)
확실히 key라는 단어로 동사를 구성해야 하기 때문에 is를 사용해야 하며, is를 생성할 때 사용해야 하는 Attention이 cabinets보다 key에 더 많이 적용되어야 합니다. 즉, 입력값은 [CLS] token, 출력 값은 ‘단수’가 되어야 합니다. 이런 Task에 대한 3가지 예시 그림을 살펴봐보시죠.
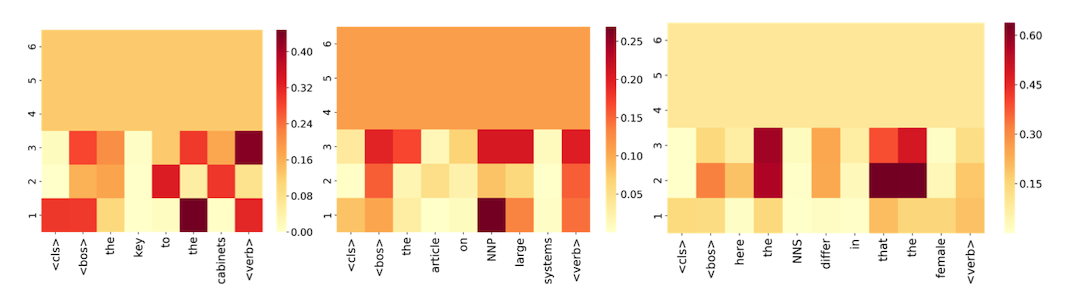
각 예시의 Layer 별 Attention 양태의 공통점은 상위 Layer에서 입력 값들에 대한 Attention의 차이가 전혀 없어진다는 것입니다. 즉, 모든 Token에 대하여 공평한 Attention을 갖고 있어 변별력이 없어지는 것이며, 모두 똑같은 정보를 함유하고 있음을 나타냅니다.
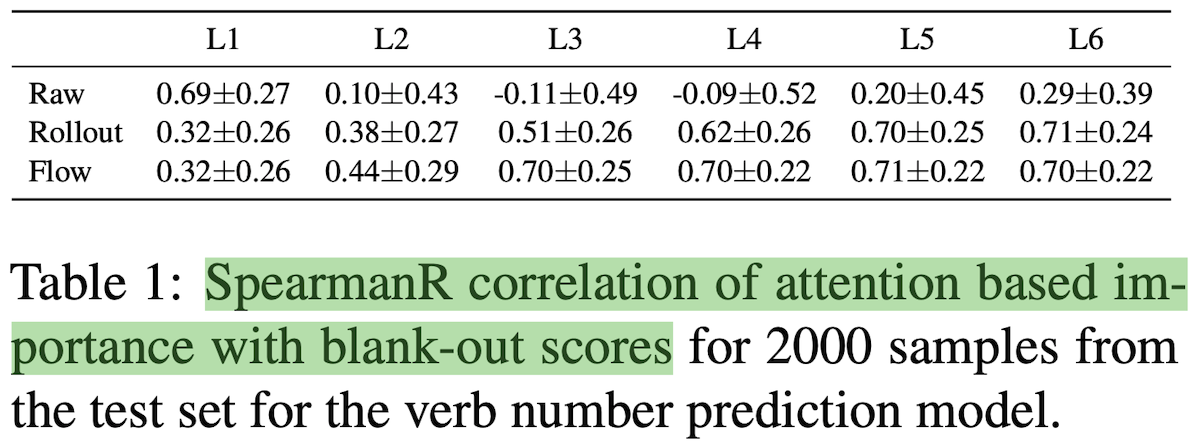
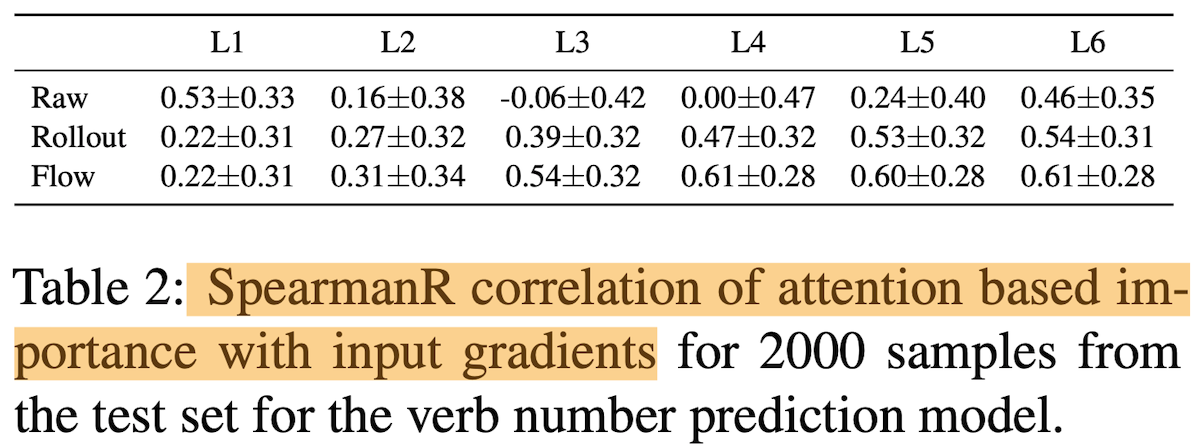
Attention과 다른 설명력의 수단인 ‘Blank-out’과의 Spearman’s rank correlation을 계산했을 때, Raw Attention은 상관도가 매우 낮습니다. 아래의 표에서 Blank-out, Gradient 그리고 Attention과의 상관도를 계산해보면, 첫번째 Layer를 제외하고 다른 층에서는 모두 상관도가 매우 낮음을 볼 수 있습니다.
Attention Rollout and Attention Flow
Attention Rollout
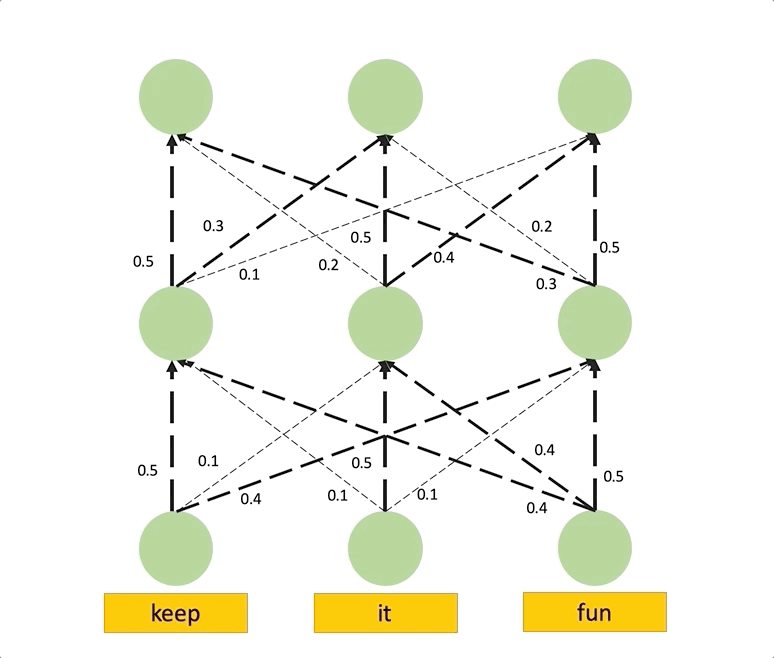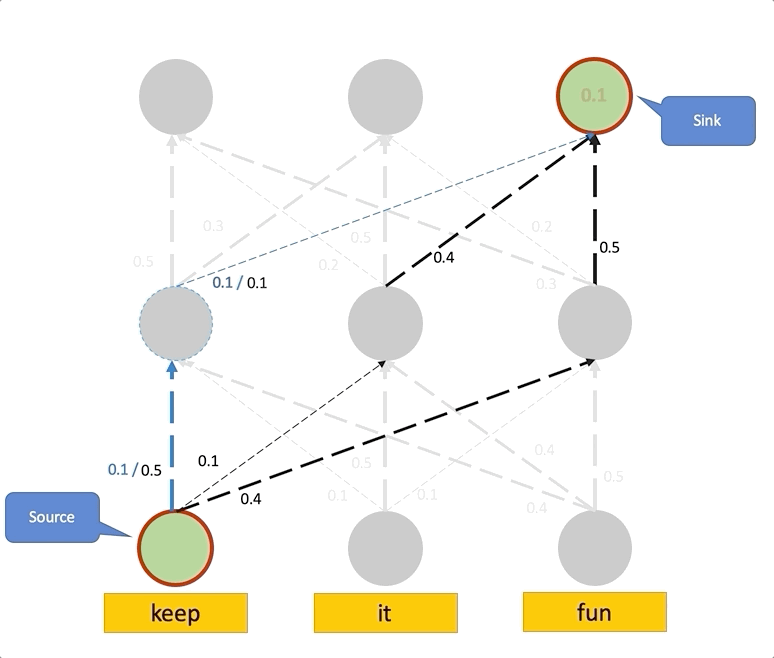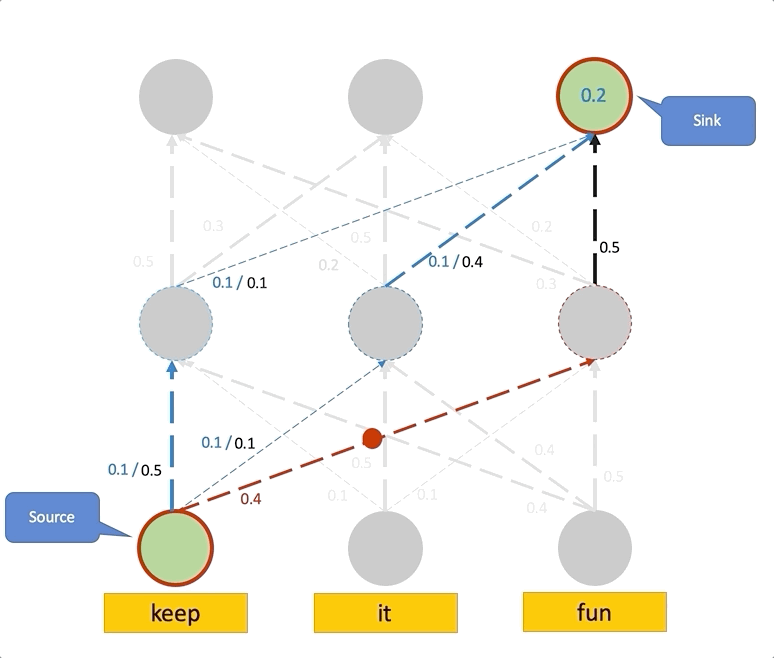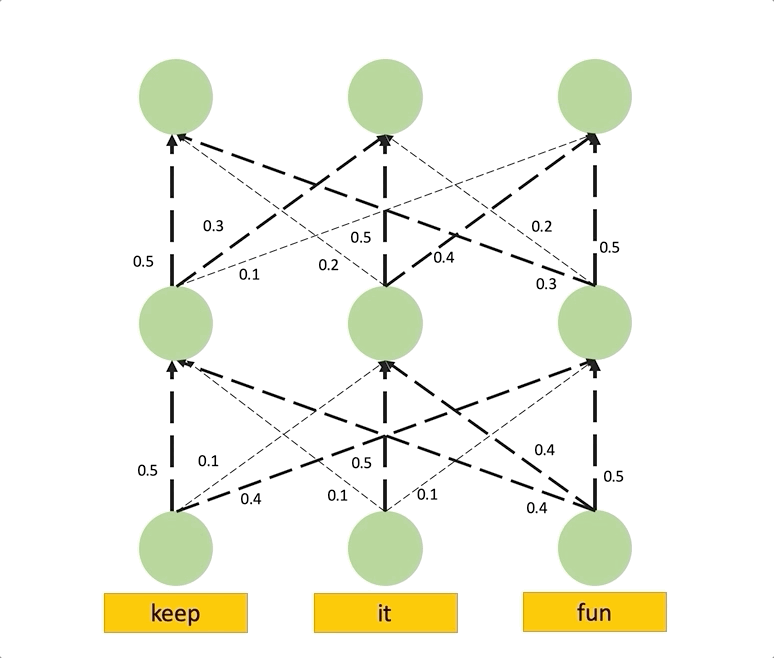
위에서 Raw attention이 Layer가 높아질수록 Uniform하다는 것을 알게 되었으며, 이는 Attention이 모든 곳에서 똑같은 정보를 가지고 있음을 나타냈습니다. 따라서 이 현상을 없애기 위해선 Lower Layer의 정보를 위까지 최대한 끌어와야 하며, 이는 최종 Layer의 Attention을 계산하기 위해 이전의 모든 Path에서 오는 Attention을 더해주는, 즉 낮은 층에서 Rollout을 진행하여 구성합니다.
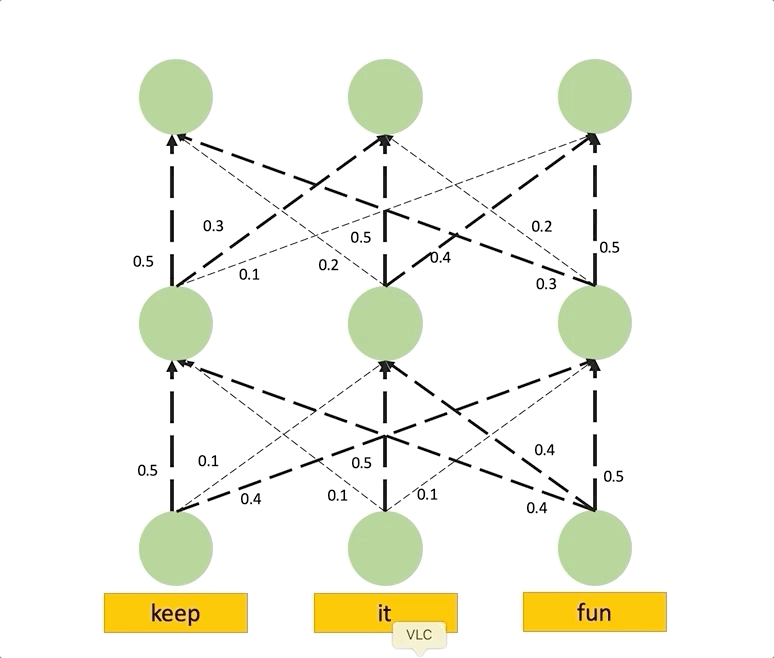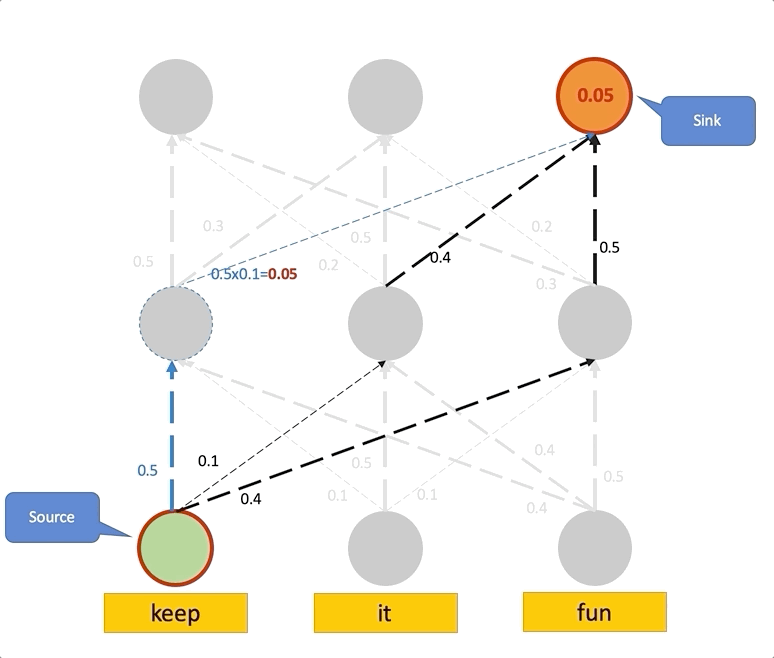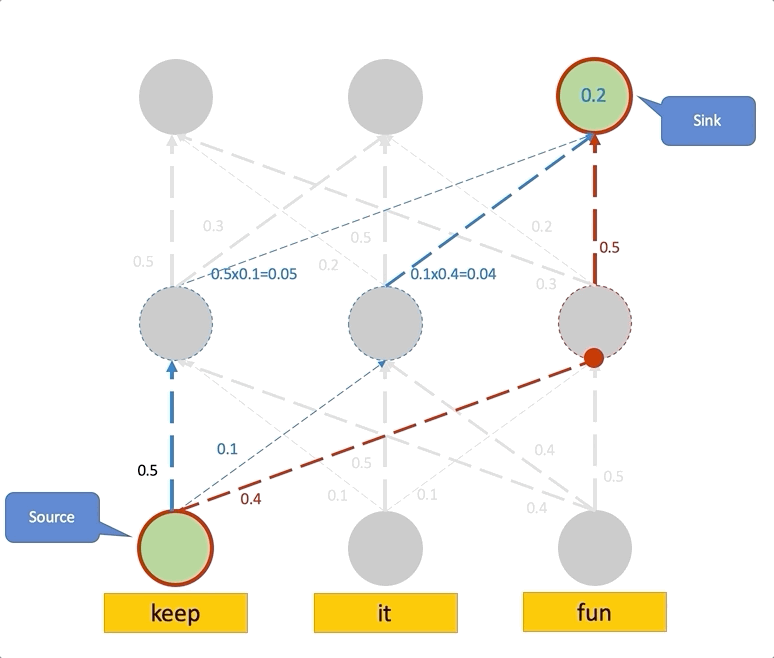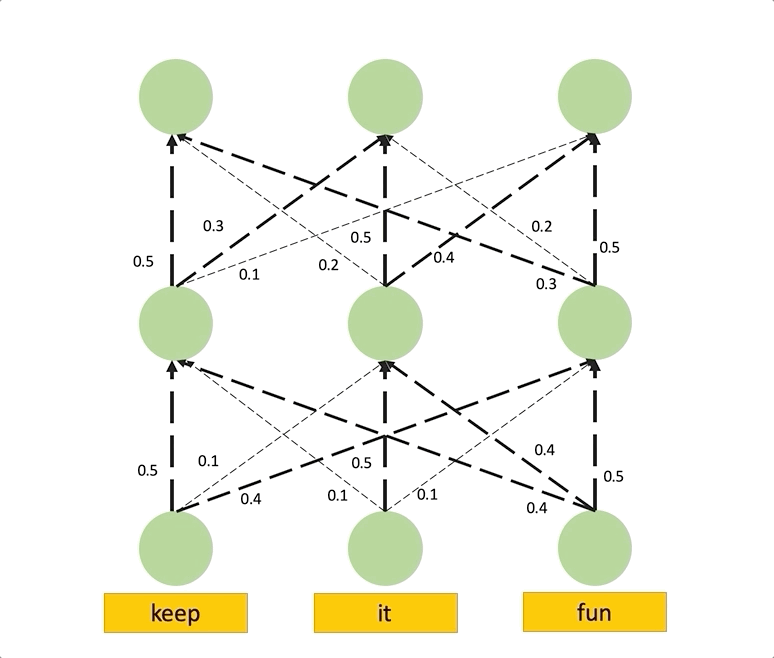
Attention Flow
해당 개념은 Maximum Flow라는 개념을 통해 Attention을 대체할 수 있는 개념을 구성합니다. 사실 본 개념은 잘 이해를 하지 못하겠으나, “Attention Flow is Shapley Value”와 같은 논문을 통해, Attention보다 더 좋은 설명력의 가정을 갖고 있음이 증명되어 효용성은 크다고 생각합니다. 해당 부분은 Maximum Flow를 이해한 뒤 다시 작성하겠습니다.
Analysis and Discussion
Attention, Rollout, Flow는 첫 Layer에서는 동일한 가중치를 갖고 있습니다. 하지만 층이 높아질수록 양태가 나르게 나타나며, 새로운 개념들(Rollout, Flow)에서는 Residual Connection의 힘이 약해지는 것을 볼 수 있습니다. 또한 기존의 Attention과 다르게 높은 층에서 역시 Attention으로서 다양한 값에 가중치를 주는 모습을 볼 수 있습니다.
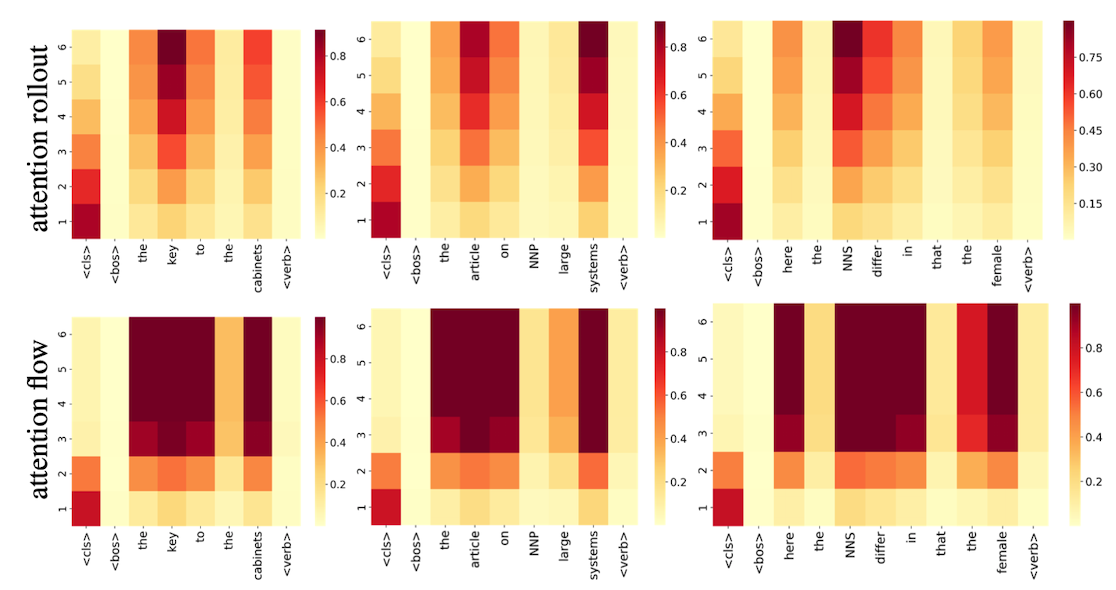
두 개념의 가장 큰 차이점으로는 결과로서 볼 수 있는데, Attention Flow는 Set of Tokens, 즉 중요한 여러개의 Token에 대하여 고르게 Attention이 퍼져있는 반면, Attention Rollout은 좀 더 Specific 한 Attention을 얻어낼 수 있다고 합니다.
둘 중에 어느 개념이 더 Attention을 대체하기 위한 개념이냐는 질문에 대한 답은 Attention Flow라고 합니다. 이는 Attention 가중치를 바라보는 관점의 차이라 하나 자세한 이해는 힘들었습니다. 간략하게만 말씀드리자면, Attention Rollout은 Attention Flow보다 엄근진한 가정을 많이 사용하나, 가정을 최소화하는 Attention Flow가 더 좋다… 이런 류의 결론입니다.
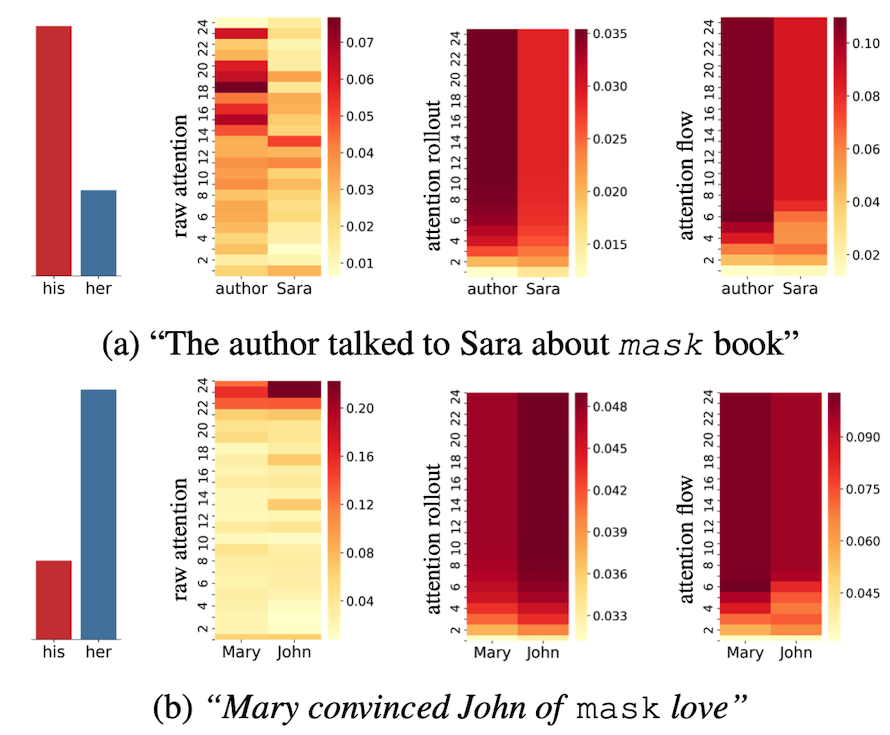
추가적으로 논문에서는 문장 내 Masking 되어 있는 부분의 대명사를 맞추는 Task도 추가합니다. (a) 예시에서는 his가 정답이며 이 때 Attention은 Sara라는 여성 이름보다는 Author에 더 많은 가중치를 주어야 합니다. 기존 Attention은 이것을 달성하지 못하지만, Rollout과 Flow는 달성하고 있습니다. 또한 (b)의 예시에서는 Attention Flow만이 해당 역할을 잘 달성한 것을 볼 수 있습니다.
Wrap-up
저는 본 논문을 살펴보면서 계속 든 생각이,
설명력이 좋은 모델이 성능이 좋은 모델이 되어야 되지 않나?
라는 생각이 들었습니다. 즉, Attention Flow를 Attention 대신 사용 또는 추가를 해 사용하면 더 좋은 성능이 나타나지 않을까? 라는 의문입니다. 그런데 논문 초반에 “우리는 모델의 성능을 높일 생각으로 Attention Flow를 만든 것이 아니다” 라고 하는데 도무지 그 구체적인 이유를 잘 모르겠습니다.
이번 주의 글또 게시글을 빠르게 마무리 하겠습니다. 감사합니다.