Vision Papers Review
Paper Lists
- Vision Transformer
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
- MLP-Mixer
- Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
-
End-to-End Object Detection with Transformers (DETR $\approx$ DEtection with TRansformers)
- 어떤 task인지
- 이전 방법론 한계
- 제안하는 컨셉
Vision Transformer
Task: Classification
Vision Transformer
| 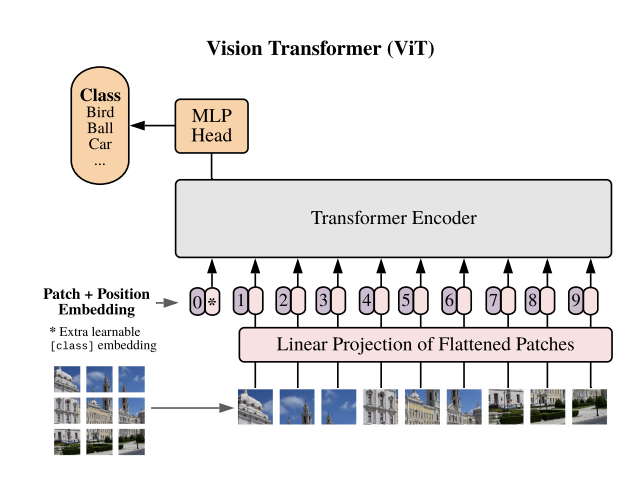 |
Vision Transformer는 이미지 분류를 위해 고안된 모델로서, 이미지의 패치를 개별 토큰으로 설정하고 위치에 대한 정보를 Position Embedding으로 더하여 Transformer Encoder의 입력으로 사용한다. Transformer의 CLS 토큰을 활용하여 문장의 분류를 진행하는 자연어에 대한 Transformer 적용과 같이 이미지에 대해서도 CLS 토큰에 대한 분류를 통해 이미지의 분류를 진행한다.
[이전 방법론 한계]
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Task: Image Captioning
Image Captioning이란, 이미지를 설명할 수 있는 문장을 생성하는 기법이다. 확실히 어렵게 느껴지는 과제이지만, Neural Network와 다양한 분류 기법, 데이터셋의 등장으로 성능이 개선되고 있으며 특히 Attention을 통해 이미지의 다양한 부분을 Caption에 반영할 수 있게 되었다. 이전에는 CNN 층들을 지속적으로 사용하여 나타나는 요약 정보를 통해 Downstream Task를 진행했지만, CNN은 이미지 내의 전체적으로 퍼져있는 정보들을 모두 활용하기에는 적절하지 않다.
Related Work
- RNN / Seq2Seq 기법들이 많이 활용되었으며 Encoder-Decoder 프레임워크를 많이 사용한다. 그 이유는 이미지를 문장으로 번역하는 컨셉이기 때문이다.
- 다른 방식으로는 Object Detection을 사용해, 먼저 이미지에서 캡션에 포함될 Object를 탐지한 후 각 Object들을 사용해 Caption을 생성한다.
Models
Model은 이미지를 Input으로 받고 그에 대한 Caption 문장 토큰을 하나씩 생성해 나간다. 이미지의 Feature를 얻어내기 위하여 CNN을 활용하기는 하지만, 전체 이미지를 지나치게 함축한 High Level Representation 대신, Low Level Representaion을 사용하여 이미지의 전체 정보를 활용하고자 한다.
이후 Encoder-Decoder Framework에서 Caption을 생성하기 위해 사용하는 Attention의 종류는 두 가지이며, Hard / Soft Attention의 차이는 0/1 또는 0~1로 Attention을 나타내느냐이다.
- Hard Attention
- Soft Attention
Encoder: Fintuning하지 않은 VGGnet
Decoder: LSTM + Attention
DETR
Object Detection은 본디 두 가지 큰 분류로 나뉘어 진다.
- 1-stage detector: YOLO
- 2-stage detector: Faster R-CNN
이들의 차이는 detector 앞단에 후보 지역을 추천하는 Region Proposal Network (RPN)의 존재 여부이다. 일반적으로 1-stage detector는 추론 속도가 빨라 real-time task에 사용되지만 정확도 면에서 2-stage detector에 비해 낮다.
Transformer를 사용한 Object Detection은 RPN과 같은 Hand-crafeted Engineering이 필요 없는, End-to-End Model을 지향하며, Attention 메커니즘을 통해 전역적 정보를 활용함에 따라 큰 물체 탐지에 대해 Faster R-CNN 보다 높은 성능을 보여준다.
제안 컨셉
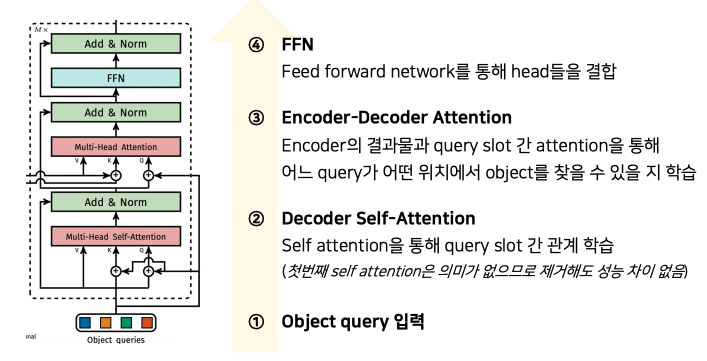
-
이미지에 CNN을 적용하여 Feature Map 획득
-
Feature Map을 Transformer의 입력값으로 사용할 수 있도록, 1x1 convolution layer를 사용해 토큰 임베딩 차원으로 축소
-
Transformer Encoder의 Positional Encoding에 2D fixed sine positional encoding 사용
-
Encoder: Attention을 통해 feature map의 pixel과 pixel 간의 관계 학습 Locality 중심의 CNN과 다르게 전역 정보를 학습해 이미지를 이해하며, Detection Task에 걸맞게 학습되어 이미지 내 Object의 위치 또는 관계를 학습한다.
-
Decoder: 이미지 내에 존재하는 object의 클래스 및 위치 출력 Transformer는 Permutation invariant하기 때문에 입력 값이 서로 달라야 서로 다른 출력을 뱉어낼 수 있어, 학습이 가능한 Positional Encoding을 랜덤하게 초기화하여 입력으로 사용한다.
Object Query는 Detect하고자 하는 object의 위치를 나타냄
-
즉, Decoder의 목적은
- Encoder-decoder attention을 통해 이미지의 어느 부분을 봐야 하는가?
- Self attention을 통해 자신들의 역할을 분배하여 최적의 일대일 매칭을 수행할 수 있는지 (Object Query와 이미지 내의 부분과의 매칭)
Swin Transformer
기존 ViT 모델은 분류 문제를 풀기 위한 모델로 제안이 되었으며, Transformer의 구조를 거의 그대로 사용하였지만 Text와 다른 이미지의 특성을 반영한 부분은 크게 없다. 또한 Transformer를 그대로 사용하는 것은 그의 문제점도 복사해오게 되는데 이는 Token 수가 증가함에 따라 연산량이 Quadratic하게 증가한다는 것이다.
따라서 Swin Transformer (Shifted Window)는
- Transformer 구조에 이미지의 특성을 반영할 수 있는 방법
- 기존 ViT 모델보다 더 적은 연산량을 갖는 방법
을 제안한다.
텍스트와 다른, 이미지의 고유한 특성으로는 다음과 같다.
- 해상도 (Resolution)
- 물체의 크기 (Scale of visual entities)
이런 이미지의 특성을 Transformer에 반영하기 위하여 두 가지 Main 전략을 활용한다.
-
Patch Merging
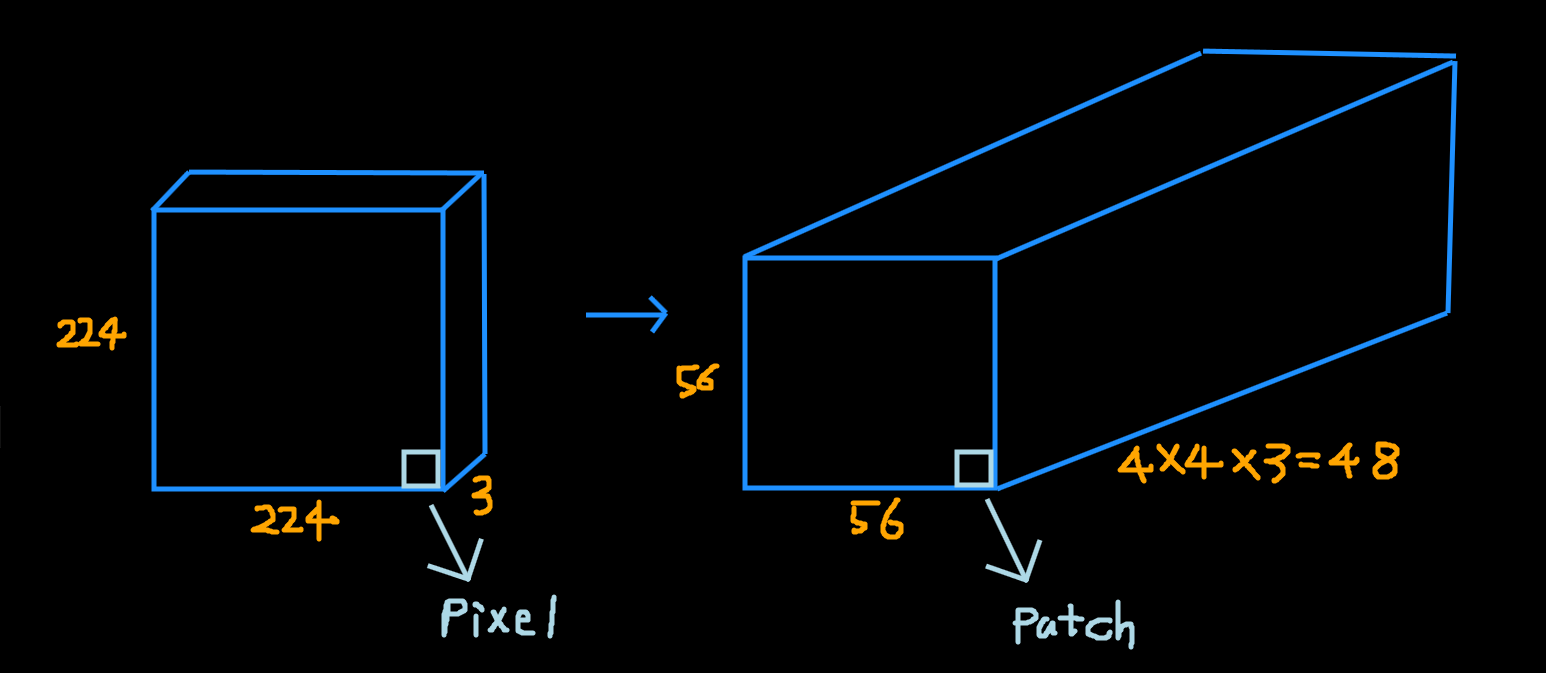
출처: https://visionhong.tistory.com/31
Input Image의 하나의 패치 정보를 Merge 하는 단계를 거치며, 이는 단순히 구역 내 같은 정보량을 Transformer의 입력으로 활용하기 위한 변형이다.
-
W-MSA / SW-MSA
-
Relative Position Bias
Swin-Transformer는 ViT와 다르게 Position embedding을 Input에서 더해주지 않고, self-attention 과정에서 relative position bias를 추가한다.