석사 3학기가 이제 거의 끝나가는 시점에서, 옛날부터 갖고 있던 질문에 대하여 깨달은 점이 하나 있습니다.
“논문을 자세히 읽어야 하는가? 아니면 빠르게 많이 읽어야 하는가?”
답은 무조건 후자인 것 같습니다. 특히 연구에 대한 주제 선정과 결과를 빠르게 결정해야 하는 석사의 경우에는 더욱 더 강조되는 부분인 것 같습니다. 따라서 휘뚜루마뚜루 식으로, 물론 너무 내용을 왜곡해서 읽지는 않는 선에서 빠르게 읽는 것을 최근 들어 많이 연습하고 있으며 이번 글에서는 이를 기반으로 작성한 DST 논문들의 간략한 요약을 진행하고자 합니다.
Dialogue State Tracking
- TRADE 링크: https://arxiv.org/pdf/1905.08743.pdf
- SUMBT 링크: https://arxiv.org/pdf/1907.07421.pdf
- SOM-DST 링크: https://arxiv.org/pdf/1911.03906.pdf
- Transformer-DST 링크: https://arxiv.org/pdf/2010.14061v2.pdf
- Effective Sequence-to-Sequence DST 링크: https://aclanthology.org/2021.emnlp-main.593.pdf
- COCO-DST 링크: https://arxiv.org/pdf/2010.12850.pdf
TRADE
모델 구조
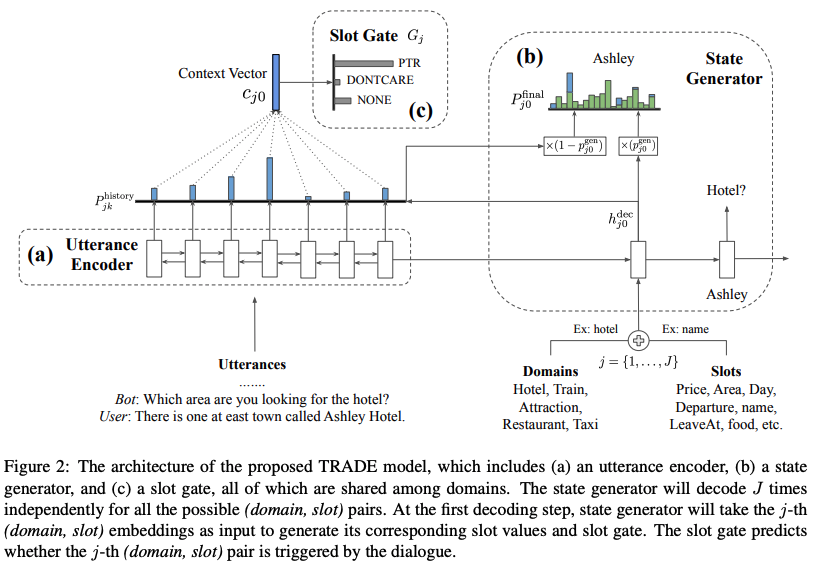
TRADE의 전체적인 구조는 포인터 제너레이터 네트워크 (See et al., 2017)과 같이, Seq2Seq 디코딩 과정에서 입력 값에 대한 정보를 어휘 집합 분포에 추가하여 슬롯에 대한 값을 한 토큰씩 생성해낸다.
먼저 인코더에서는 시스템과 사용자 발화의 결합 형태인 입력값에 대하여 양방향 GRU를 사용해 인코딩한다. 이를 통해 구해낸 은닉 벡터를 통해 디코더에서 토큰에 대한 생성을 진행하며, 정해진 슬롯 개수만큼 생성을 반복한다. 디코더는 단방향 GRU를 사용하며 은닉 벡터를 통해 어휘 집합을 구성하며, 해당 어휘 집합만을 생성을 진행 하는 것이 아닌, 입력 값의 은닉 벡터들에 대한 어텐션 분포를 구성하여, 그에 대한 분포를 어휘 집합에 가중 합을 진행한다. 본 방식을 통해 어휘 집합에는 존재하지 않지만, 입력 문장에는 들어가는 토큰들에 대한 생성 이 가능하여 Out-of-vocabulary(OOV) 문제를 해소할 수 있게 된다.
TRADE는 인코더와 디코더에 더불어 슬롯 게이트(Slot Gate)를 추가적으로 구성하여, 디코더에서 생성한 값 들을 사용할지 또는 다른 값으로 대체할지를 결정한다. 디코딩 과정에서 계산한 어텐션을 활용하여 모든 입력 값에 대한 문맥 벡터를 구성한 뒤, PTR, DONTCARE, NONE을 결과로 나타내는 분류기에 통과시킨다. 분류기 에서 PTR의 값을 도출하면 디코더를 통해 생성한 값을 해당 슬롯의 값으로서 설정하지만, DONTCARE, NONE 이 등장하면 생성 값을 무시하며 대체한다. 모델에 대한 최적화는 토큰을 생성하는 디코더와 슬롯 게이트에 대한 손실에 대한 가중합으로 진행한다.
실험 결과
SUMBT
모델 배경
SUMBT 이전 DST 모델들은 각 턴마다 슬롯에 해당하는 값을 생성하지만, 데이터셋에 새로운 값이 추가된다면 다시 전체적으로 학습해야 하기 때문에 모델의 유연성(Flexibility)이 부족했다. 이에 본 연구에서는 범용적, 확장 가능한 DST가 가능한 모델을 제안하며, 이는 특정 슬롯의 값이 시스템과 사용 자의 발화 내에 존재한다고 가정한다. 이런 시각은 Question-Answering, Machine Comprehension 과제와 유사 하며, 이를 DST에 대입하면 슬롯(Domain-slot-type)을 질의, 해당하는 값 (Slot-value)를 답이라고 상정하는 것이다.
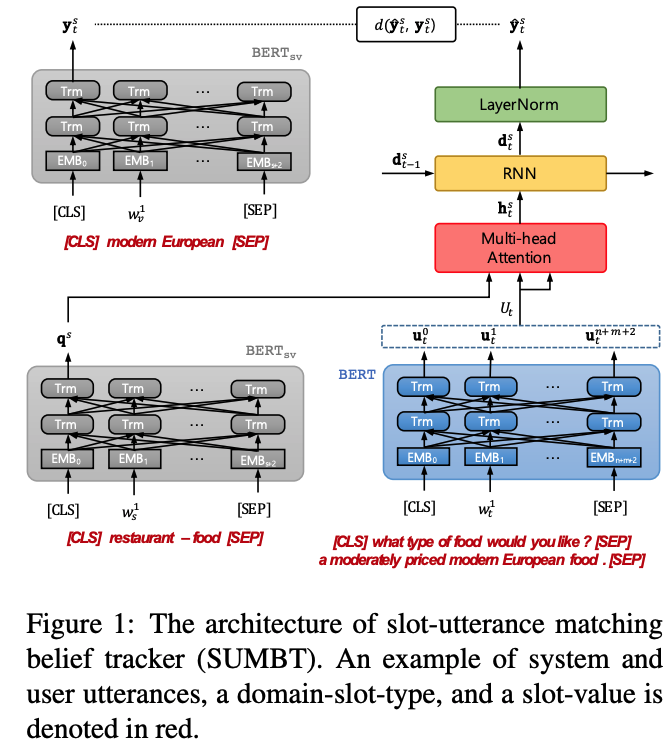
모델 구조
모델 구조는 네 가지 모듈로 이루어진다.
먼저 Contextual Semantic Encoders는 사전 훈련된 BERT 언어 모델을 활용하며, 시스템, 사용자 발화에 대한 인코딩과 슬롯, 값에 대한 인코딩을 진행한다. 시스템, 사용자 발화에 대한 인코딩은 발화 내의 토큰들의 은닉 벡터를 구할 수 있게 되고 (그림-파란색 상자), 슬롯(e.g. restaurant-food)과 값(e.g. modern European)에 대해서는 [CLS] 토큰을 통해 요약된 표상을 얻을 수 있다.
모든 슬롯에 대한 일관된 벡터를 구하기 위하여 해당 BERT 언어 모델(그림-회색 상자)의 파라미터는 고정한다. 이후 Slot-Utterance Matching Network (그림-빨간색 상자)를 거치며, 이는 슬롯과 발화의 관계 정보를 파악하기 위한 멀티 헤드 어텐션 과정이다. Contextual Semantic Encoders에서 계산한 슬롯의 은닉 벡터를 쿼리로써 활용하고, 발화 내의 각 토큰을 어텐션 키, 어텐션 값으로 활용하여 문맥 벡터를 만든다. 다음 Belief Tracker (그림-노란색 상자)는 RNN을 사용하며 기본적인 DST 모델들의 생성 과정과 같다. 마지막으로 생성된 토큰에 대한 벡터와 정답 값을 고정된 언어 모델을 통해 나타낸 벡터와의 거리가 최소가되도록 하는 것을 훈련 목표로 삼는다.
(3) 실험 결과
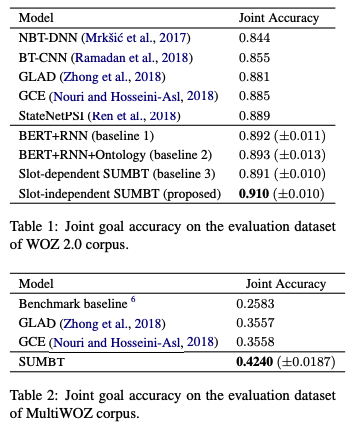
SOM-DST
모델 구조
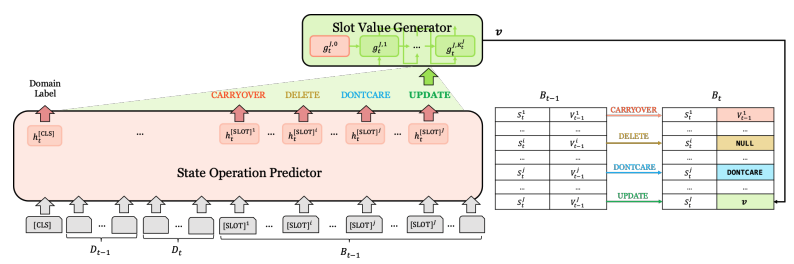
SOM-DST는 DST를 2개의 하위 과제로 분리하여 효과적으로 슬롯에 해당하는 값을 생성해내며, 이를 통해 기존 DST 모델들이 가진 비효율을 개선함과 동시에 좋은 성능을 보인 모델이다. 첫번째 하위 과제는 State Operation Predictor(SOP)로서 특정 슬롯이 디코더에서 어떤 처리(Operation)가 적용되어야 할지 결정하는 인코더이다.
BERT 언어 모델을 사용하며 발화와 각 슬롯에 대한 입력 값이 주어졌을 때, 각 슬롯의 요약 정보를 담고 있는 [SLOT] 토큰에 대한 분류를 통해 슬롯에 대한 처리를 결정한다. 처리의 종류로는
- 이전 턴의 값을 그대로 유지하는 CARRYOVER ,
- 이전 턴의 값을 삭제하는 DELETE,
- 이전 턴의 값을 변경하는 UPDATE,
- 해당 처리로 값을 나타내는 DONTCARE가 있다.
이후 Value Generation 하위 과제를 진행 하며 이는 SOP에서 UPDATE 처리를 할당 받은 슬롯에 대하여 값을 생성하는 절차이다. TRADE와 유사하게 포인터 제너레이터 네트워크(See et al., 2017)의 복사 메커니즘을 활용하여 값에 대한 최종 분포를 결정한다.
모델 결과
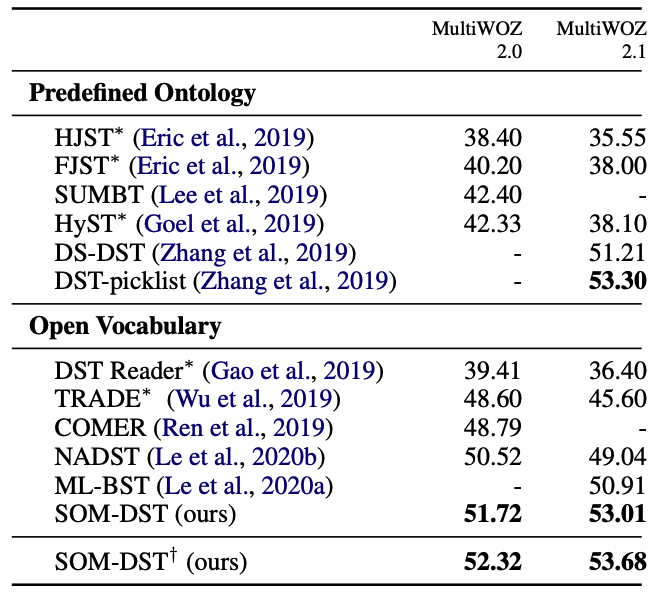
Transformer-DST
모델 배경
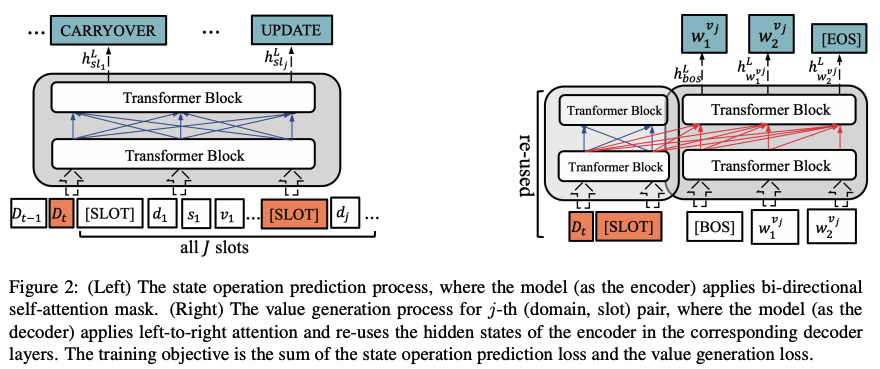
SOM-DST 이후의 DST 모델들은 SOP와 VG 절차를 기저로 연구가 진행되었다. 해당 과정의 문 제점은 두 절차가 독립적으로 훈련이 되어 SOP는 BERT 인코더만을 훈련시키며 VG는 RNN 디코더만을 훈련 시켜 상호간의 영향을 주지 못한다. Transformer-DST는 독립적인 모듈들의 훈련 과정을 서로에게 종속적으로 만들어 DST의 성능 향상을 도모한다.
모델 구조
Transformer-DST의 입력은 한 턴 이전 시점과 현재 시점의 발화와 모든 슬롯을 결합하여 사용한다. 구성한 입력 값을 사전 훈련된 BERT 인코더를 통해 각 토큰의 은닉 벡터를 구성하며 각 슬롯의 정보를 요약한 [SLOT] 토큰에 대하여 분류를 진행하여 SOP를 진행한다.
이후 디코더로서 허깅페이스의 BERTForSeq2SeqDecoder를 활용하며 이를 통해 Transformer의 Seq2Seq 과정을 나타낸다. 그림의 우측에 나타난 Re-used는 인코더에서 계산한 은닉 표상을 그대로 활용하며 현재 턴의 발화와 UPDATE 처리를 할당 받은 [SLOT]의 것을 활용한다. 실험 결과 인코더의 모든 입력을 생성 과정의 어텐션 키와 어텐션 값으로 활용하면 오히려 성능이 하락하는 결과가 나타났으며, 각 슬롯에 해당하는 값을 한 토큰씩 생성해낸다.
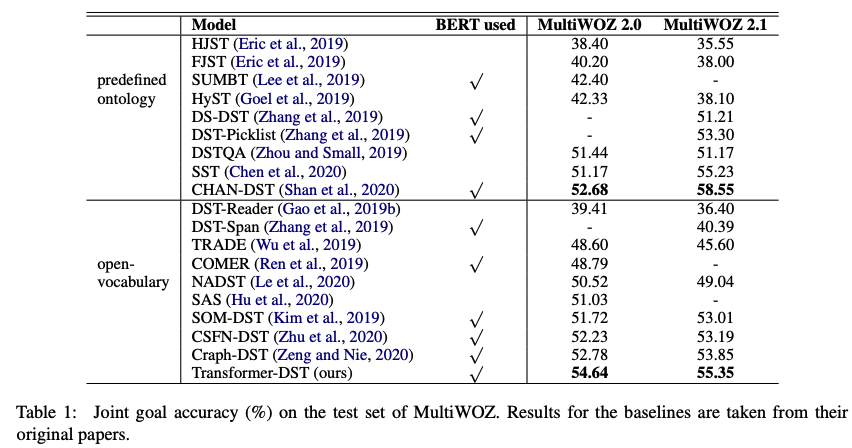
Transformer-DST와 SOM-DST의 에폭 별 JGA를 비교했을 때, Transformer-DST의 수렴 시점이 더 빠르고, 테스트 성능이 일관적으로 높았다. 효율성 관점에서는 Transformer-DST가 SOP를 진행하지 않고 모든 슬롯에 대한 값을 생성해내는 TRADE와 Latency가 유사하였다. 즉, JGA와 같은 Metric 관점에서는 우수하지만 사용자의 요구사항을 빠르게 파악해야 하는 DST의 핵심 속성인 속도가 느리다는 단점이 있다.
실험 결과
Effective Sequence-to-Sequence DST
모델 배경
DST 모델들은 기본적으로 Seq2Seq 모델을 기반으로 설정하고 있으며, 이로써 각 슬롯에 대한 값을 생성해낸다. 이전 모델들은 Seq2Seq 구조에서 인코딩, 디코딩 절차를 변화시켜 DST의 성능을 향상 시키려는 노력을 진행했으나, 본 연구는 모델 속에 포함된 사전 훈련 언어 모델들 중 어떤 훈련 방법을 거친 모델이 DST 과제에 더 좋은 성능을 낼 수 있는 지에 대하여 조사하였다.
![]()
언어 모델의 사전 훈련 방식은 크게 두 가지로 나타나며, 이는 Masked Span Prediction과 Auto-regressive Prediction이다.
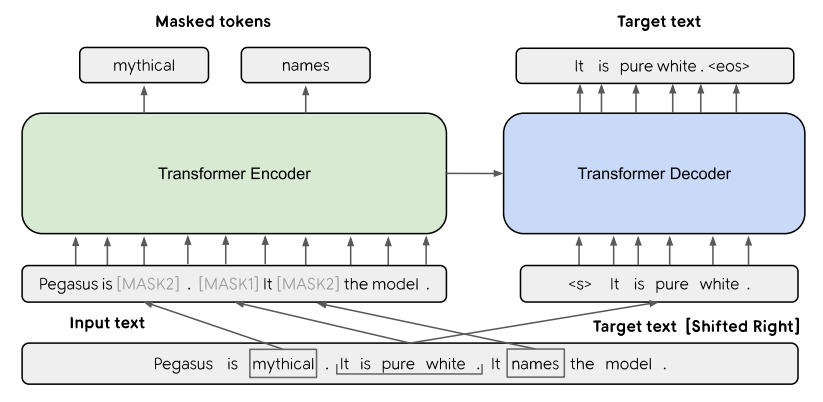
전자의 경우 입력 값의 일부를 마스킹 처리를 한 뒤 해당 값들을 맞춰 가는 과정을 의미하며 BERT가 대표적이다. 후자의 경우는 다음 토큰을 예측하는 절차를 통해 사전 학습이 이루어지며 GPT(Radford et al., 2018) 등이 활용한다.
본 연구의 실험에서는 T5를 두 사전 훈련 방식으로 각기 훈련 시킨 뒤, DST를 진행했을 때의 성능을 비교하여 사전 훈련 방식을 비교하며 아래 그림에서 span과 ARLM으로 각기를 지칭한다. 또한 본 연구에서는 Masked Span Prediction을 사전 훈련 방식으로 활용하는 Pegasus (Zhang et al., 2019)에 대한 DST 성능을 평가하였으며, 그 이유는 해당 모델이 단순한 마스킹 절차를 사용하는 것이 아니라 주요 문장이 마스킹 되는 훈련을 거쳐 문서 요약을 위해 활용되기 때문이다(위의 그림). 문서 내 주요 문장 을 선택하는 과제와 유사하기에 DST 역시 해당 모델을 통한 생성이 성능 향상에 도움이 될 것이라 는 가정을 갖고 있다.
실험 결과
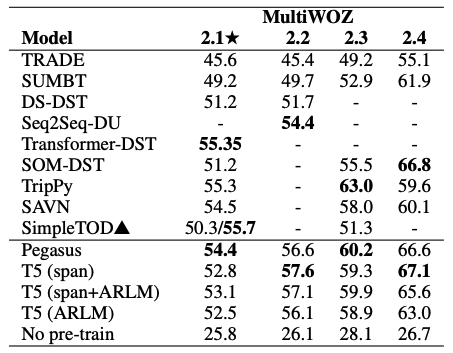
위의 그림의 결과는 다음과 같이 정리할 수 있다. 첫 번째로 T5의 span이 포함된 결과가 일관적으로 높은 것 으로 보아 Masked Span Prediction으로 사전 훈련된 모델을 DST에 활용하는 것이 성능 향상에 더 유리할 것이다. 두 번째로 Pegasus 모델의 성능이 모든 데이터셋에서 우수하여, 문서 요약을 Downstream Task 로서 활용한 사전 훈련 모델이 DST 성능 향상에도 도움이 된다는 것을 나타내었다.
COCO-DST
모델 배경
COCO-DST는 기존 연구의 성능을 발전시키는 방향의 연구인 Incremental Research가 아닌, 과제 자체의 내재하는 문제를 해결하기 위하여 새로운 관점 및 방향을 제시하는 Innovative Research이다. DST는 MultiWOZ로 대표되는 한정적인 데이터 셋에 대해 많은 연구가 진행되고 있으며, 이는 현실 대화의 특징을 잘 반영하지 못하여 일반화 성능이 낮을 수 있다. 구체적으로, 현실 대화에서는 벤치마크 데이터셋 (MultiWOZ)에서 학습하지 않은 값이 등장할 수 있으며, 다양한 종류의 유저가 존재할 수 있다.
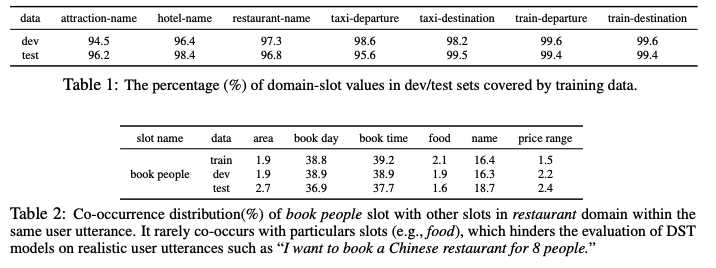
MultiWOZ는 훈련, 테스트 데이터가 비슷한 방법으로 수집되었으며, 두 데이터의 슬롯 내에 포함된 값들의 중복이 많이 일어나 학습 시 나타난 값이 테스트에서 재등장하지 않는 경우가 없다 (위의 그림). COCO-DST의 연구 목적 은 DST가 MultiWOZ에 편향되어 있을 것이라는 가정 아래, 대화의 흐름은 유지되지만 새로운 유저 의 응답을 받았을 때도 시스템이 성공적으로 DST을 할 수 있는지 알아보고자 한다.
즉, 기존에 존재하는 데이터셋과는 다른 내용의 대화를 반사실적(Counterfactual) 대화라고 나타내고 이를 생성하는 방식을 효과적으로 제어할 수 있는(Controllable) 방법을 제시한다.
모델 구조
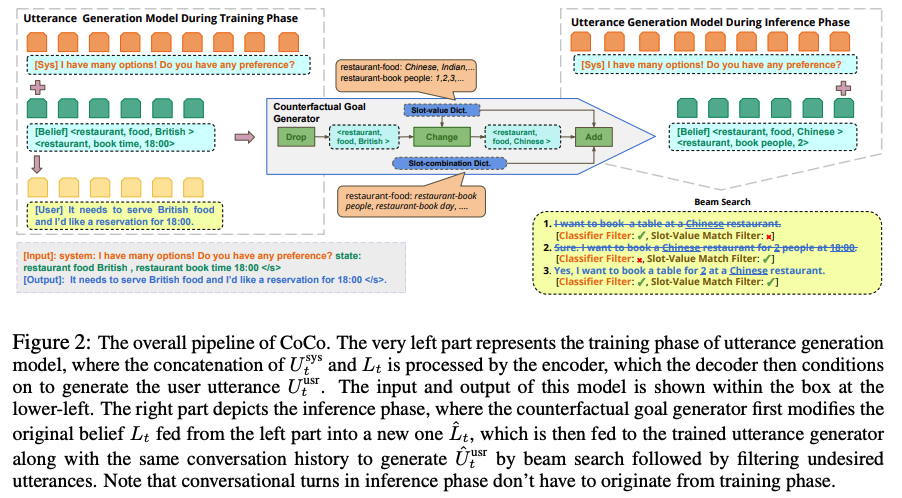
위의 그림에서 COCO에 대한 모델 구조를 살펴볼 수 있으며, 3가지 단계로 나타난다.
먼저, 훈련 과정 속에서 시스템 발화와 현재 대화 상태를 입력으로 받아 사용자의 발화를 생성해내는 조건부 언어 모델을 훈련 시킨다. 이후 반사실적 대화 상태를 생성하기 위하여 기존 상태를 입력으로 받아 연속적으로 3가지 과정(Drop, Change, Add)을 확률적으로 시행하며, 예를 들어 (restaurant, food, british)의 상태를 해당 과정을 통해 (restaurant, food, chinese)로 변경하는 것이다.
마지막으로 반사실적 대화 상태와 결부하는 반사실적 발화를 생성하기 위하여 앞서 훈련 시킨 조건부 언어 모델을 활용하며, 입력 값으로 기존의 시스템 발화와 발사실적 대화 상태를 활용한다. 생성된 사용자 발화는 필터링을 통해 조건에 결부하지 않는 발화를 제거하여 사용한다.
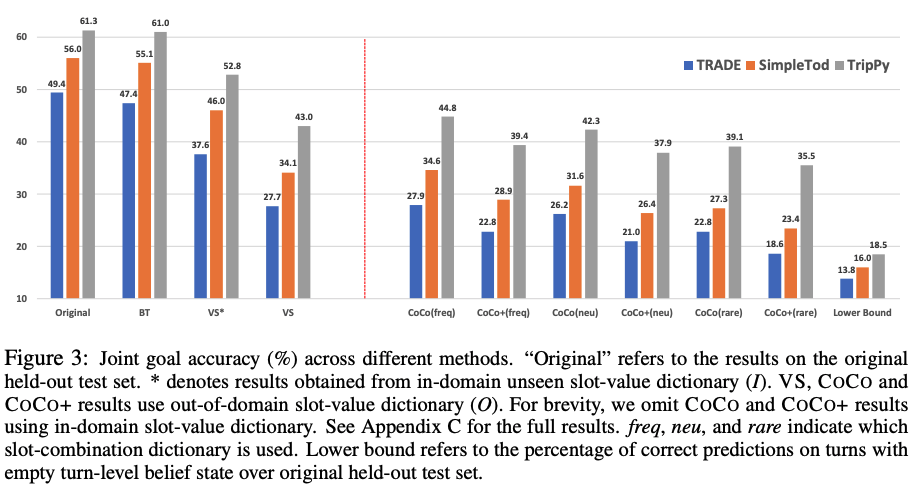
아래 그림에서 COCO 방법으로 반사실적 발화와 대화 상태를 통해 생성한 데이터와 기존 데이터셋 (MultiWOZ)에 대한 테스트 성능을 비교했을 때, 전자의 성능이 월등히 낮아지는 것으로 현재 DST 모델들이 기존의 벤치마크 데이터셋에 편향이 되어 있음을 밝혀냈다.