안녕하십니까. 고려대학교 산업경영공학부 석사과정, DSBA 연구원 윤훈상입니다. 지난 포스트에서는 XGBoost 논문을 읽고 정리를 해보았습니다. 대중적으로 많이 사용되는 알고리즘이지만, 내용 자체는 매우 난이도가 높았습니다.
Introduction
이번 포스트에서는 XGBoost를 실제로 활용하는 시간을 가져보겠습니다. 이를 위해 먼저 XGBoost에서 등장하는 알고리즘적 개념을 열거해보겠습니다.
-
Gradient Tree Boosting(Newton Boosting)
-
Loss Function
-
Split Finding Algorithms
- Basic Exact Greedy Algorithm
- Approximate Greedy Algorithm
- Global & Local Variant
- Weighted Quantile Sketch
- Sparsity-aware Split Finding
열거한 알고리즘적 개념은 결국 시스템적인 혁신을 가능케 하기 위한 수단일 뿐입니다. 위의 알고리즘을 사용하여, Column Block for Parallel Learning이 가능하도록 하는 것이지요.
본인도 XGBoost를 공모전이나 프로젝트를 진행할 때 간혹 사용한 적이 있습니다. 그럴 때마다, 파라미터를 최대한 Default로 두거나 Number of Round(GBM Tree 갯수)와 같이 이해가 쉬운 파라미터만 HyperParameter Search로 진행한바 있습니다.
따라서 이번 기회에 이전 시간에 작성했던 포스트인, XGBoost와 Hyper Parameter Optimization with GP / TPE를 통해 XGBoost 구현체에는 어떤 파라미터가 있는 지 쭉 살펴보고, 최적화를 진행해보고자 합니다. 이를 통해 Hyper parameter를 찾는 과정을 통해 최적의 결과를 얻더라도, 어떤 파라미터들을 탐색했는지에 대하여 알아보는 시간을 가질 수 있을 것입니다.
XGBoost 파라미터는 크게 3가지로 나뉩니다.
- General Parameters: 어떤 Booster를 사용할 것인지
- Booster Parameters: 선택한 Booster를 어떻게 구성할 것인지
- Learning Task Parameters: Regressions, Classification 등과 같이 어떤 목적으로 XGBoost를 사용할 것이지
- (CLI parameters): CLI에서 사용할 때의 파라미터
“해당 파라미터들을 최대한 놓치지 않고, 제가 중요하다고 생각하지 않아도 이를 필요로 하는 사람이 있을 수도 있기에 하나씩 정리해보겠습니다” 라고 처음에는 생각했으나, 몇 가지 파라미터들은 파악이 어려웠기에 최대한 많이 조사하여 정리했습니다.
파라미터의 개념은 논문 내용을 참고하였고, 실제 어떻게 활용되는 지는 메뉴얼을 참고하였습니다.
General Parameters
-
booster[default=gbtree]booster란 기본이 되는 Function을 의미합니다. GBM은 모델을 연속적으로 계산하는 것이므로, 보통 Tree Based Model을 엮는 것으로 많이들 생각하나, 결국 Linear Model을 연속적으로 이어도 됩니다. 따라서
-
gbtree: Gradient Boosting Tree
-
gblinear: Gradient Boosting Linear Function
gblinear에 대해서 확실하게 개념을 설명한 자료를 찾기 힘들었습니다. Gradient Boosting을 진행함에 있어, Tree 기반 모델을 사용하지 않고, Linear Model을 사용한 듯 보이나, 정확한 절차는 파악하지 못했습니다. 하지만 해당 포스트를 살펴보면, 데이터가 존재할 때, gblinear와 gbtree가 만든 모델의 생김새, 그리고 결국 gbtree가 더 성능이 좋음을 test한 결과를 보여줍니다.
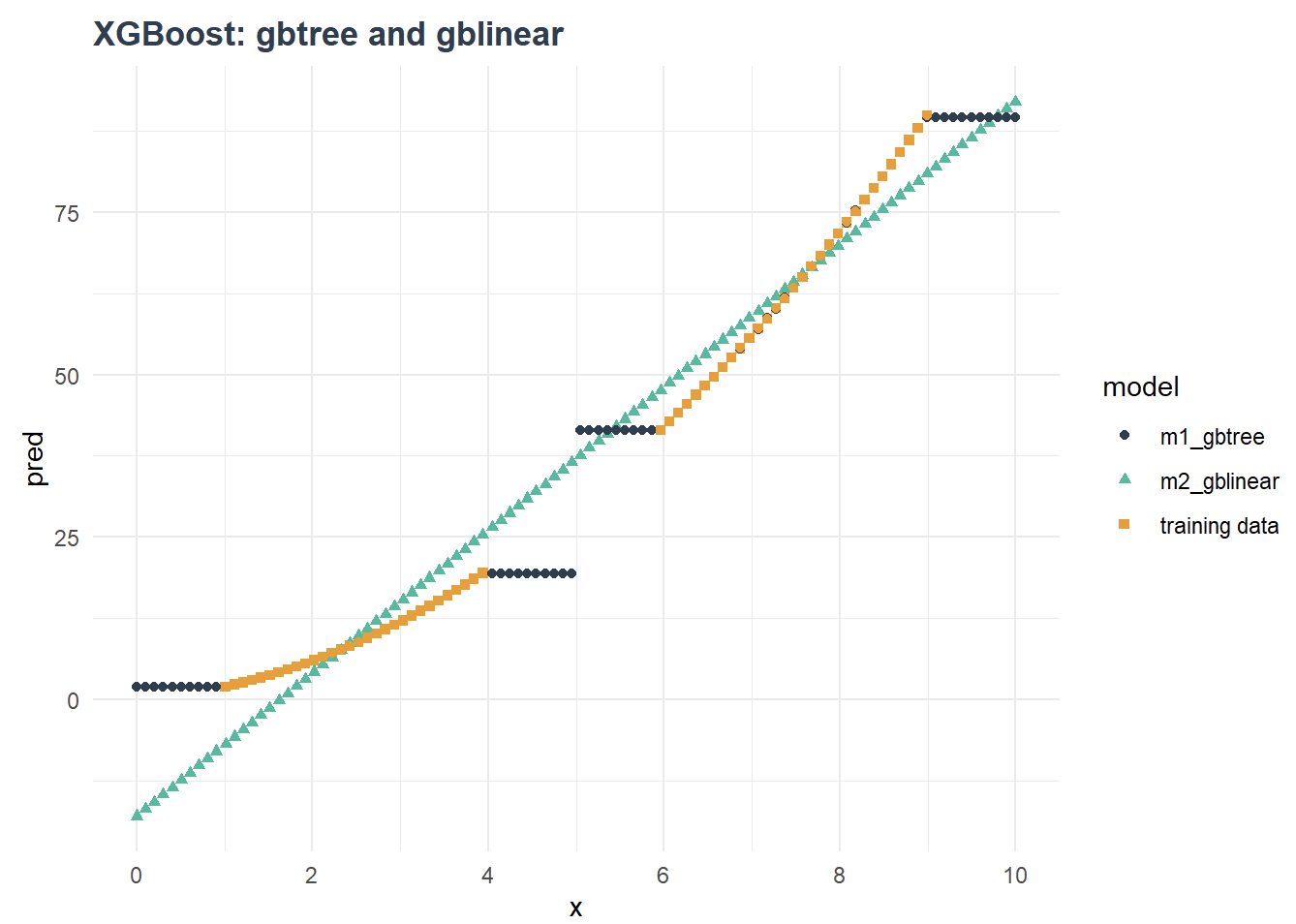
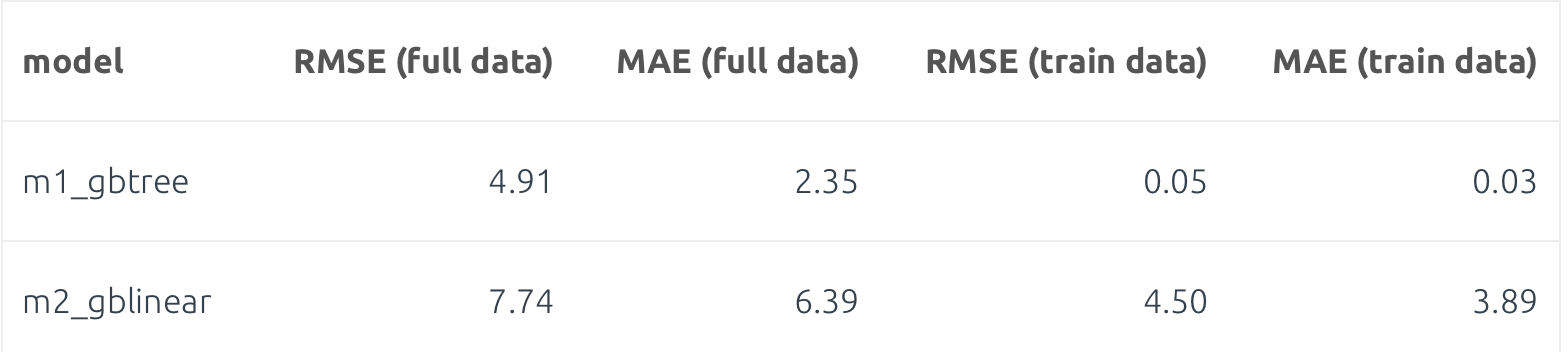
-
dart: Dropouts meet Multiple Additive Regression Trees
-
CART (Classification And Regression Trees): CART는 MART / DART와 이름 꼴이 비슷하나, 자체적으로 Gradient Boosting Tree의 역할을 하는 것이 아니라, Decision Tree의 일종입니다. 이는 XGBoost에서 살펴보았듯이 분류를 진행한 뒤 분류 노드들에 대한 Node Value를 설정하여 Tree를 구성합니다.
-
MART(Multiple Additive Regression Trees): MART는 저희가 흔히 아는 GBRT, Gradient Boosting Regression Trees와 동치입니다. 다중으로 더해져가면서 구성되는 Tree라는 뜻이 이를 반영해주는데, 굳이 GBRT 대신에 MART를 사용한 것은 이전에 존재했던 알고리즘인 CART를 의식해서 생성한 이름이지 않을까 싶습니다.
-
DART(Dropout meet Multiple Additive Regression Trees): DART는 MART에 Dropout을 적용한 것입니다. 2015년에 탄생한 것으로도 추측할 수 있듯이, 딥러닝에서 사용하는 Dropout 기법을 활용했다고 논문에서 언급을 합니다.
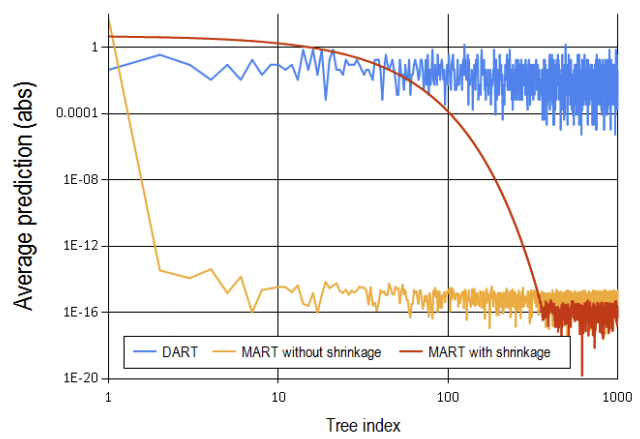
논문에서 발표한 결과 Plot을 살펴보면 DART이전에 활용한 MART에 Shrinkage를 적용한 결과보다 DART가 안정적인 Prediction을 보여주는 것을 볼 수 있습니다.
즉, gbtree는 MART(GBRT)를 Boosting Algorithm을 사용하면서 Boosting의 대상을 CART로 지정했음을 알 수 있습니다.
-
-
-
verbosity[default=1]Verbosity는 Message Printing의 단계를 말합니다. 사전적 의미로는 ‘수다스러움’을 말하는데, 결과에 대해서 얼마나 자세하게 말해줄지에 대한 파라미터입니다.
-
validate_parameters[default to false, except for Python, R and CLI interface]설정한 Input Parameter들이 실제로 사용되는 지에 대한 검증을 합니다.
-
nthread[default to maximum number of threads available if not set]사용할 Thread 갯수
-
disable_default_eval_metric[default=false] -
num_pbuffer[set automatically by XGBoost, no need to be set by user] -
num_feature[set automatically by XGBoost, no need to be set by user]사용하는 Feature의 갯수로서, 자동적으로 데이터의 최대 Feature 갯수로 정의합니다.
Booster Paramter
-
eta[default=0.3, alias:learning_rate] - Overfitting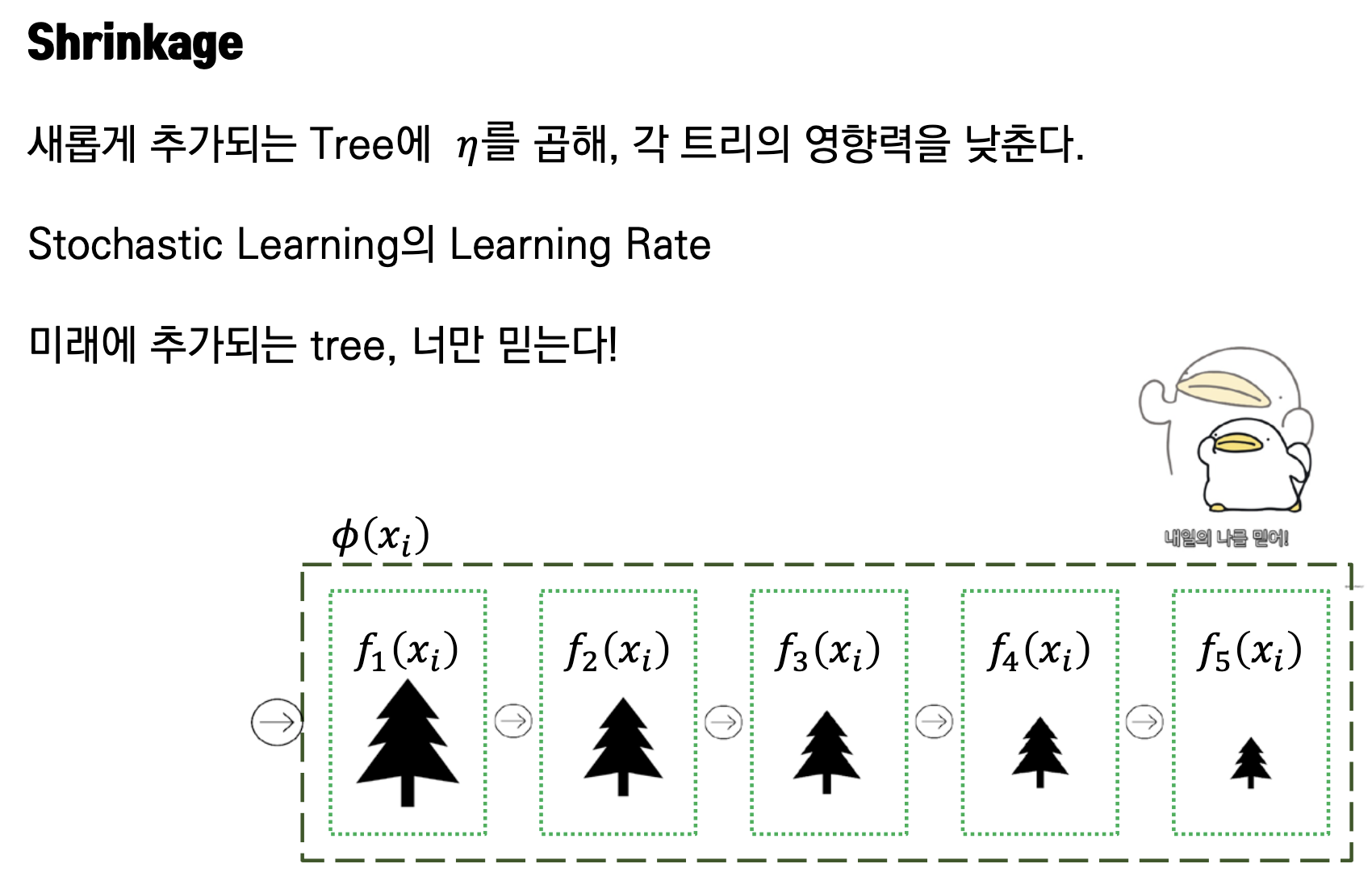
Boosting 계열의 모델들은 Shrinkage라는 개념을 사용하여 Overfitting을 방지합니다. 지속적으로 추가되는 Tree Model들의 영향력을 낮추는 식으로 진행되며, 이때 $\eta$를 모델에 곱하여 트리의 영향력을 낮춥니다.
range: [0,1]
-
gamma[default=0, alias:min_split_loss] - OverfittingMinimum split loss의 의미를 갖는 $\gamma$는 Tree Split을 했을 때, 줄어야 하는 최소 Loss양입니다. 이를 넘지 못하면, 분기를 진행하지 않습니다.
Range: [0,$\infty$ ]
-
max_depth[default=6] - OverfittingTree의 최대 깊이입니다. Tree 깊이를 증가시키면 더욱 복잡한 모델이 등장하여 과적합의 가능성이 커집니다.
Tree_method 파라미터를
hist로 설정하고, growing policy가lossguided일 때만 0을 허용합니다. XGBoost는 깊은 트리를 구성할 때 메모리를 엄청나게 사용합니다! -
min_child_weight[default=1] - OverfittingSplit을 했는데 Child의 Node들의 instance weight가
min_child_weight를 넘기지 못하면 Split하지 않습니다. 하지만 document에는 Left / Right Node의 모든 Instance인지, 둘 중 하나의 Instance인지에 대하여 명확하게 말하지는 않지만, 후자의 경우인 것 같습니다. 이는 정답을 파악 시 수정하겠습니다. -
max_delta_step[default=0] - Overfitting해당 파라미터는
eta와 더불어 정규화 관련 파라미터입니다.eta가 이미 그 역할을 제대로 하고 있고, 본 파라미터는 논문에서 소개되지 않았기에 docs에도 크게 필요없다고 말하지만, Logistic Regression의 class imbalance를 잡아주는 역할을 할 수 있다고 합니다. -
subsample[default=1] - OverfittingSubsample은 훈련 데이터에서 Sample Data를 뽑는 것을 말합니다. 이를 0.3으로 설정한다면, 매 tree를 구성할 때마다 데이터에서 0.3만큼
sampling_method에 따라 추출한 후 훈련합니다. -
sampling_method[default=uniform]subsample를 하는 방법을 말합니다.uniform: 각 훈련 데이터가 뽑힐 확률이 Uniform Distribution을 따릅니다.gradient_based: 각 훈련 데이터가 뽑힐 확률이 regularized absolute value of gradients $(\sqrt{g^2 + \lambda h^2})$ 에 비례합니다. 이는 Tree method가gpu_hist일때만 사용 가능한데,hist가 기본적으로 weighted quantile sketch에 대응하며, 해당 sketch를 사용할 때 gradients를 필요로 하기 때문으로 추산됩니다.
-
colsample_bytree,colsample_bylevel,colsample_bynode[default=1]subsample은 데이터 instance에 대한 sample이었습니다. 이에 반해, colsample은 tree를 분할할 때 사용하는 Feature인 Column을 Sample한다는 뜻입니다. 즉 아래의 그림같이, 1번째 모델에는 [1,5,8]의 Column을, 2번째 모델에는 [3,4,7]의 Column을 통해 Split을 진행합니다.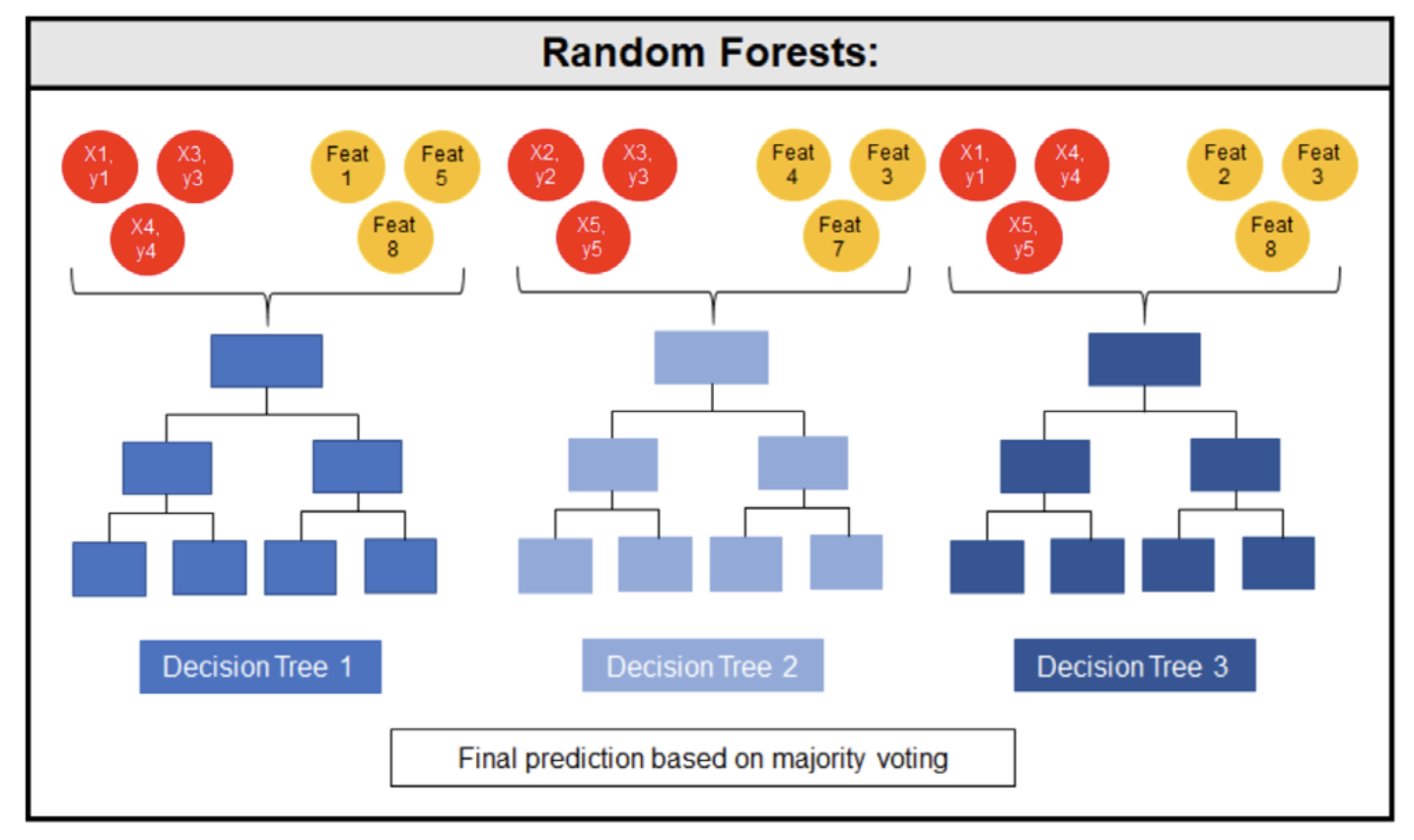
colsample_bytree: Tree를 처음 구성할 때, Column을 sample 합니다.colsample_bylevel: Tree의 depth마다 Column을 sample 합니다.colsample_bytree에서 Sample된 Column 내에서 진행합니다.colsample_bynode: Tree의 Split이 진행될때마다 Column을 sample 합니다.colsample_bylevel에서 Sample된 Column 내에서 진행합니다.
-
lambda[default=1, alias:reg_lambda]$\Omega(f_t) = \gamma T + \frac{1}{2}\lambda\sum\limits_{j=1}^{T}w_{j}^2$ , 모델의 정규화는 다음의 식으로 이루어지는데 $\lambda$인 부분에 L2 정규화를 진행할 때 사용하는 파라미터 입니다. 즉 모델의 갯수 제한을 하는 $\gamma$와 다르게, 모델 내부의 가중치를 조정합니다.
-
alpha[default=0, alias:reg_alpha]$\lambda$인 부분에 L1 정규화를 진행할 때 사용하는 파라미터 입니다.
-
tree_methodstring [default=auto]XGBoost가 Tree를 구성하는 방식에 대한 알고리즘입니다.
approx,hist,gpu_hist에서는 Distributed Training을 지원합니다.-
auto: 최적의 method를 휴리스틱하게 판단합니다.작은 데이터셋에 대해선
exact를 사용하고, 큰 데이터 셋에서는 나머지 파라미터를 사용합니다. 특히 큰 데이터 셋에 좋은 성능을 보이고 싶다면,hist와gpu_hist를 사용하는 것이 좋습니다.논문에서
appox는 approximate greedy algorithm을 뜻하며,hist는 approximate greedy algorithm 사용시 Weighted Quantile을 사용하는 것입니다.
-
-
sketch_eps[default=0.03]tree_method=approx일때만 사용가능합니다. 그 이유는 $\epsilon$(eps)는 Percentile을 얼마나 잘게 나눌지에 대한 파라미터로서, Candidate Points의 숫자와 연관이 있기 때문입니다. 예를 들어, $\epsilon$ = 0.03이라면, $\frac{1}{\epsilon}$개의 candidate points가 생길 것이기에 33개가 나타나게 됩니다.즉, $\epsilon$이 작을수록, Quantile을 더 잘게잘게 쪼게는 것이 됩니다. 하지만 이를 딱히 조정할 필요는 없다고 합니다.
-
scale_pos_weight[default=1]데이터가 Imbalanced할 때 사용하는 파라미터이며, 논문에서 사용한 Criteo같은 데이터에서 필요로 합니다. 이는 sum(negative instances) / sum(positive instances)로 계산되며, 최대한 Class 간의 비율을 맞추려고 하는 것입니다.
-
grow_policy[default=depthwise]새로운 노드가 tree에 더해지는 방식을 정의하며,
tree_method가hist일때만 사용가능하다.depthwise: Root와 가장 가깝게 Split을 진행한다.lossguide: loss의 변화가 가장 큰 Split을 진행한다.
-
max_bin[default=256]tree_method가hist일때 활용됩니다.연속형 변수에 대하여 bins의 최대값을 정합니다. 숫자를 크게잡으면, Computation이 많이 요구되지만, 분기의 Optimality는 확보할 수 있습니다. 이는 Histogram 기법을 활용할 때, 사용하는 Histogram의 Bins를 좁게 잡기 때문에 가능한 것입니다.
-
num_parallel_tree[default=1] - Number of parallel trees constructed during each iteration. This option is used to support boosted random forest.
Dmatrix & Cross Validation
Dmatrix
xgboost에서는 dmatrix를 사용합니다. 이는 xgboost에서만 고유하게 사용하는 데이터 구조입니다.

Dmatrix가 무엇이 그렇게 대단한지에 대하여 찾아보고 싶었지만, 공식문서에는 다음과 같이 memory 효율성과 훈련 속도 증가를 얘기하고 있습니다. 또한 다른 자료들에도 많은 내용은 없지만, numpy에 기반한다고 합니다.
이에 제 생각에는 dmatrix는 xgboost가 제시한 성능 향상의 방법을 구현하기 위한 수단으로 예상됩니다. 예를 들어, Compressed Column Storage(CSC)나 Block Sharding 같은 시스템적인 개선을 달성하기 위해 Dmatrix에 미리 기능을 삽입한 것입니다.
즉, Dmatrix로 인해 예측에 대한 성능보다는 속도가 향상될 수 있을 것 같습니다.
Dmatrix는 xgboost내에서 사용하는 것임을 생각해보면, XGBClassifier와 같이 scikit-learn으로 포장한 것 같은 함수에서는 사용할 수 없습니다. xgboost.train() / XGBoost.cv와 같이 xgboost 자체로부터 기인한 함수만이 대상이 되며, 결국 DMatrix를 사용하지 않는 scikit-learn을 활용한 구현보다는 xgboost 패키지 자체를 활용하는 것을 추천드립니다.
1 | |
Cross Validation
새로운 데이터에 대한 강건한 예측을 하기 위해선 Cross Validation을 통해 파라미터를 찾는 것이 더 유리합니다. 따라서 xgboost의 파라미터를 찾음에 Cross Validation을 이용하려 하며, 이에는 두 가지 방법이 있습니다.
-
Cross Validation with scikit-learn
scikit-learn의 cross_val_score 함수를 이용하여, cv fold를 정하고, 모델에 X와 Y를 넣는 방식으로 진행합니다.
1
results = cross_val_score(model, X, Y, cv=kfold) -
Cross Validation with xgboost built-in
또는 xgboosts내에 있는 cross validation을 그대로 사용합니다. 저는 최대한 하나의 패키지를 사용하여 구현하는 것을 선호하므로, xgboost.cv를 사용하여 cross validation을 진행해보도록 하겠습니다.
본격! XGBoost Implementation with Hyperparamter Optimization
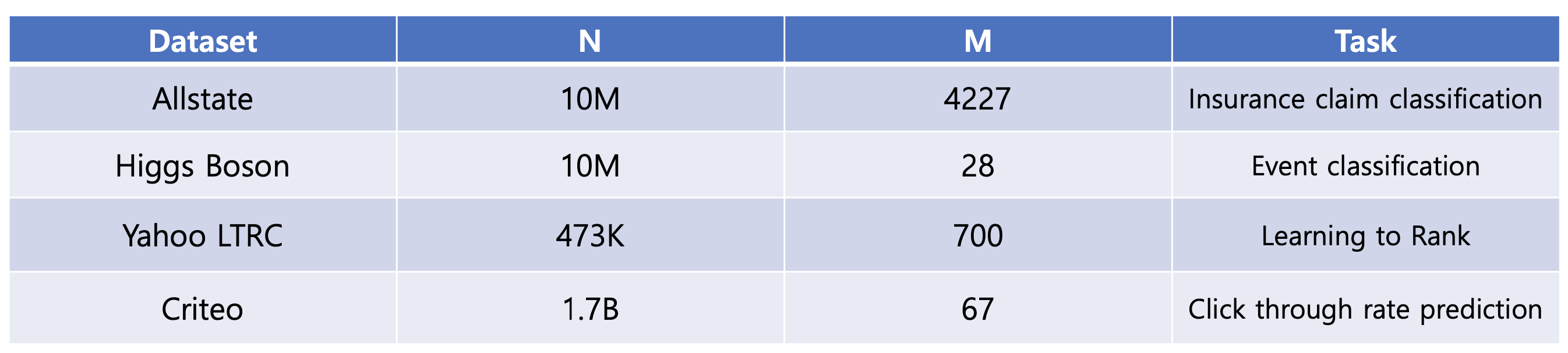
XGBoost 논문에서는 위와 같은 데이터 셋으로 Classification / Ranking / Prediction Task를 진행합니다. 본 구현에 있어선, Classification을 진행해보고자 하며, 최적의 파라미터를 찾기 위하여 지난 포스트에서 작성한 Hyperparameter 탐색에 대한 내용을 반영해보고자 합니다.
Classification을 위해 사용한 데이터셋은 위의 4가지의 데이터 중 Higgs Boson 데이터입니다. Higgs Boson 데이터셋이란 물리학계에서 주목하고 있는 입자이며 2012년에 발견되어, 2013년에는 발견한 사람들으로금 노벨상을 거머쥐게 해주었다고 합니다. 물리학에서는 물질의 발견이 끝이 아니라, 그 물질의 특성을 파악하는 것이 새로운 시작이기에 머신러닝 분야에서 이에 대한 도전으로 다양한 Task를 진행하고 있다고 합니다. XGBoost는 그 중 Classification을 진행하였으며 물질의 30개 Feature에 대하여 Label이 “tau tau decay of a Higgs boson”인지 “Background”인지에 대하여 분류하고자 했습니다. 또한 Label 뿐 아니라 물질의 Weight에 대한 Column이 있는데 Regression으로 이어지는 것 같습니다.
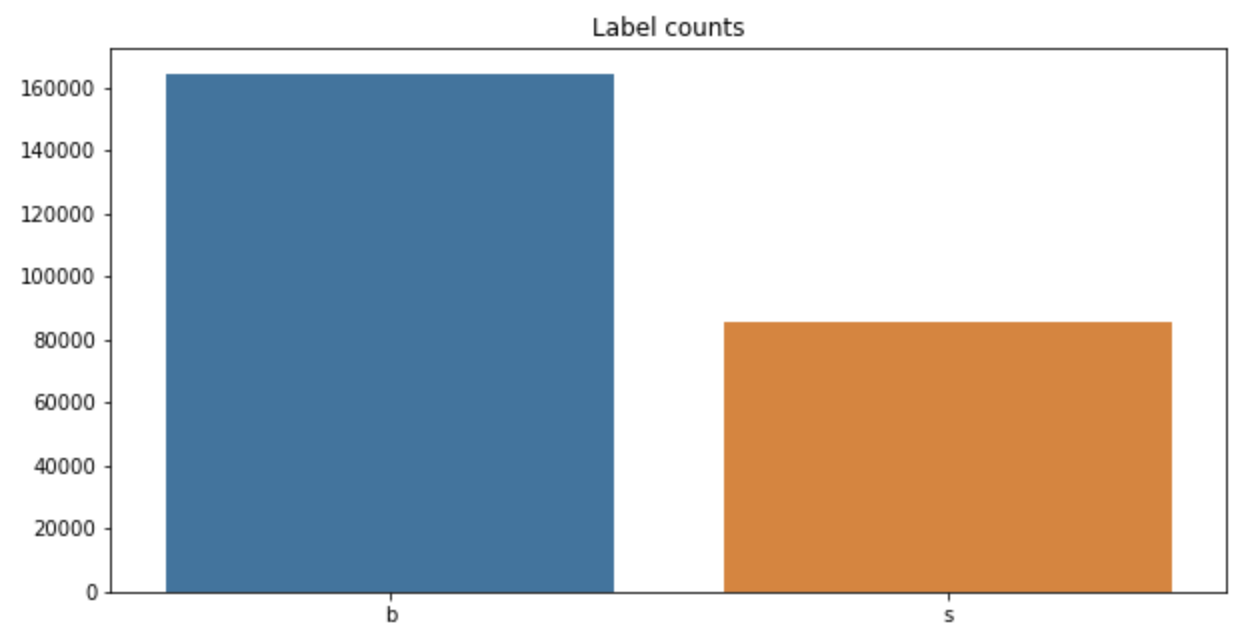
Label은 다음과 같은 비율로 나타나있으며, 자세한 EDA는 Higgs Boson에 대한 Kaggle을 참고하시길 바랍니다.
진행 절차
-
Dataset 구성
데이터셋 구성 시, train_test_split을 통해 분할합니다. 그리고 xgboost.cv를 사용할 때는 DMatrix를, XGBClassifier를 사용할 때는 train_test_split을 한 것을 그래도 Input으로 사용합니다.
-
Parameter Setting
Hyperparameter를 설정하기 위해 미리 파라미터들을 세팅합니다. Hyperopt를 통해 구성했으며, Hyperopt는 BayesOpt 패키지와 다르게 Minimum을 찾으므로 AUC를 Metric으로 설정하고, 1-AUC로 Minimum Score를 구해야 합니다. 파라미터 서칭의 대상은 아래와 같습니다.

특이사항 보고
-
tree_method: gpu_hist를 사용해야만 gpu를 사용한 연산이 가능해집니다. hist로 사용할 수 있지만, 속도 차이가 극명하게 납니다.
-
booster: xgboost에서 제공하는 booster의 종류는 세가지로, gbtree(Gradient Boosting Tree), dart(Dropout meets Multiplicative Regression Tree), gblinear가 있습니다. 앞의 두 booster는 tree based라 파라미터를 공유하지만 gblinear는 별도의 파라미터를 사용합니다. 이에 편의를 위하여 tree기반의 booster만 사용하고자 합니다.
-
xgboost는 train / cv / XGBClassifier를 사용할 때마다, 사용하는 파라미터들 넣어줘야 하는 위치가 달라집니다. 예를 들어, XGBClassifier는 boosting round (boosting 횟수)를 모델 자체에 넣지만, cv는 모델이 넣는 거이 아닌 cv 절차에 넣어줘야 합니다.
이 부분이 약간 이상한 점이, xgb.cv를 사용하게 되면 boosting 횟수마다의 cross validation score를 내뱉는다는 점입니다. 이에 따라 당연하게도 설정한 round의 마지막 round에서 성능이 최대가 될 것입니다. 따라서 사실 맨 마지막의 모델만 내뱉어도 전혀 문제가 없을 것 같은데 무슨 이유로 첫번째 boosting round부터의 score를 내뱉는지 의문입니다.
-
-
HyperOpt를 사용한 Class를 구성합니다. 본 Function과 그것을 Iteration을 하여 Surrogate Model을 통해 최적의 파라미터를 찾는 과정을 포함시켰습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52class HPOpt(object): def __init__(self, x_train, x_test, y_train, y_test): self.x_train = x_train self.x_test = x_test self.y_train = y_train self.y_test = y_test self.dtrain = xgb.DMatrix(x_train,label=y_train) self.dtest = xgb.DMatrix(x_test, label=y_test) def process(self, fn_name, space, trials, algo, max_evals): fn = getattr(self, fn_name) try: result = fmin(fn=fn, space=space, algo=algo, max_evals=max_evals, trials=trials) except Exception as e: print(e) return {'status': STATUS_FAIL, 'exception': str(e)} return result, trials def xgb_test(self, optimal, para): cla = xgb.XGBClassifier(**optimal) cla.fit(self.x_train, self.y_train, eval_set=[(self.x_train, self.y_train), (self.x_test, self.y_test)],**para['fit_params']) pred = cla.predict(self.x_test) score = para['loss_func'](self.y_test, pred) return score def xgb_cla(self, para): cla = xgb.XGBClassifier(**para['cla_params']) return self.train_class(cla, para) def xgb_cv(self, para): cla_cv = xgb.cv(dtrain=self.dtrain, params=para['cv_params'], nfold=5, num_boost_round=30, early_stopping_rounds = 10, metrics='auc') return self.train_cla_cv(cla_cv, para) def train_class(self, cla, para): cla.fit(self.x_train, self.y_train, eval_set=[(self.x_train, self.y_train), (self.x_test, self.y_test)], **para['fit_params']) pred = cla.predict(self.x_test) score = para['loss_func'](self.y_test, pred) loss = 1 - score return {'loss': loss, 'status': STATUS_OK} def train_cla_cv(self, cross_v, para): num_rounds = len(cross_v["test-auc-mean"]) cv_result = cross_v["test-auc-mean"][num_rounds - 1] loss = 1- cv_result return {'loss': loss, 'status': STATUS_OK} -
XGBClassifier와 xgb.cv에 대한 비교를 하고자 합니다.
Train
1
2
3
4
5
6
7
8
9
10
11
12obj = HPOpt(x_train, x_test, y_train, y_test) xgb_opt_class = obj.process( fn_name="xgb_cla", space=xgb_para, trials=Trials(), algo=tpe.suggest, max_evals=100 ) xgb_opt_cv = obj.process( fn_name="xgb_cv", space=xgb_para, trials=Trials(), algo=tpe.suggest, max_evals=100 ) # Classification # 100%|██████████| 100/100 [02:50<00:00, 1.70s/trial, best loss: 0.19195183395039705] # Cross-Validation # 100%|██████████| 100/100 [11:47<00:00, 7.07s/trial, best loss: 0.09611559999999986]
Test
1 | |
Train Error Loss는 XGBClassifier가 0.19 / xgb.cv가 0.09로 나타나고 있습니다. 이에 대하여 Test Error를 계산해보면 아쉽게도 Cross Validation부분에서 Overfitting이 강하게 일어나서인지 오히려 CV쪽이 성능이 낮아지는 것을 볼 수 있습니다.
하지만 Test결과로 살펴봤을 때 Cross Validation 사용 유무가 성능에 큰 영향을 주지 않은 것을 살펴볼 수 있습니다.