넷플릭스의 ‘지옥’을 보았습니다. 지옥의 내용을 스포할 수는 없지만 일단 이터널스 다섯 편을 합친 재미, 즉 5터널스급 재미라 할 수 있으며, 베놈 2 10편을 합친 10베놈급의 재미를 선사하였습니다. 약간 루즈할 수 있지만, 완강했을 때 소름이 돋았습니다.
저는 해당 드라마를 통해 기득권의 강건함과 그것에 대항하는 자들의 위대함을 보았습니다. 기득권에 대항하는 자들은 자신의 주장을 관철하기 위하여 수많은 노력과 희생을 하는 것 같습니다. 엄청난 비약이긴 하지만 오늘 말씀드리고자 하는, 그리고 지난 ‘Attention is not Explanation’과 같이 Attention의 기능을 의심하는 주장들도 기존 Mainstream에 도전하기에 주인공 같은 느낌이 듭니다.
오늘은 Attention is not explanation 에 더불어 여러 추가적인 논문들에 대한 정리를 진행해보겠습니다. 제목을 Attentionology라고 지어봤는데, 그 이유는 huggingface의 여러 목차를 살펴보던 중 BERT의 작동 원리에 대한 심도 깊은 연구를 한 논문들에 대해 BERTology라고 정의하고 있었기 때문에 차용했습니다.
Attentionology
Staying True to Your Words: (How) Can Attention Become Explanation? (Tutek&Snajder., 2020; ACL)
Attention != Explanation의 대표적인 논문인 Attention is not explanation에서는 Task와 관계 없는 대상에 Attention 이 적용되어도 성능 차이가 나타나지 않음을 밝혀냈습니다. “첫 눈이 내린 12월에 본 ‘지옥’이라는 드라마는 엄청난 드라마이다.”라는 문장이 있을 때, ‘엄청난 드라마’는 해당 문장을 긍정이라고 판단할 수 있는 대상이기에 Attention이 크게 잡혀야 하지만 ‘첫 눈’과는 관계 없습니다. 하지만 Attention은 이를 제대로 파악하지 못하고 관계 없는 ‘첫 눈’이라는 단어에 집중할 수 있으며 이것이 결과에 큰 영향을 미치지 못한다는 것입니다.
본 논문에서는 이를 Input과 Hidden Representation의 결속성이 떨어짐으로서 나타나느 현상이라고 추정하고 있습니다. 즉, 실질적으로 Attention을 계산할 때 활용되는 것은 Hidden Represenation인데, 설명력을 파악하고자 하는 대상은 입력 값이기 때문에 나타내고자 하는 설명력의 대상의 괴리가 나타나는 것입니다.
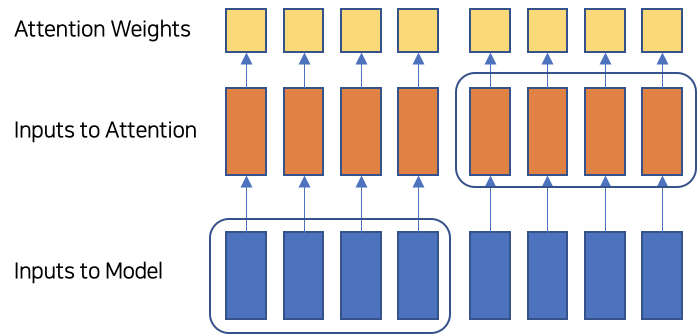
따라서, 본 논문이 살펴보고자 하는 것은,
Input과 Hidden Representation의 결속성을 증가시킨다면 Attention의 설명력을 향상시킬 수 있는지 입니다.
이를 달성하기 위하여 모델에 대한 Regularization을 진행합니다. 즉, 정규화의 목적과 같이 모델의 성능은 유지하면서 특정 조건을 만족시키고자 모델에 제한을 가하는 것입니다.
확실히 다시 강조하고 싶은 부분은, 결속성을 증가시킨다는 뜻은 곧 Input Embedding과 Hidden Represenation을 유사하게 만든다는 것입니다.
Regularization Methods
- Concat: Hidden State와 Input Embedding을 Concat
- Residual: Hidden State에 Input Embedding을 더함
- Tying: Hidden State와 Input Embedding의 차이가 벌어지지 않도록 정규화 항을 Loss에 추가 아래의 그림처럼 Loss 뒤에 1차, 2차 정규화를 적용하는 것처럼 Tying 정규화 항을 추가
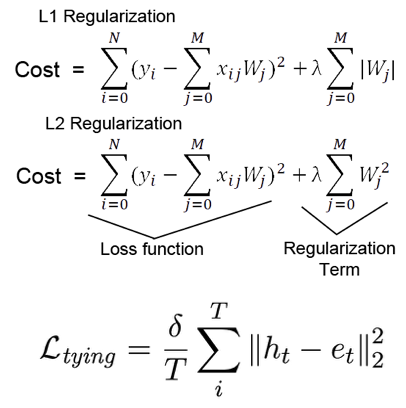
-
MLM Model: Sequence에 대해 MLM Training을 더함
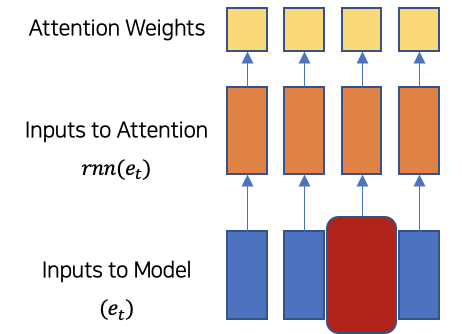
- Masked된 Hidden Representation에 대해 Linear Decoder을 통해 예측
- Encoder와 Embedding Matrix는 MLM과 Classification에서 공유
실험의 최종적인 구조는 다음과 같습니다.
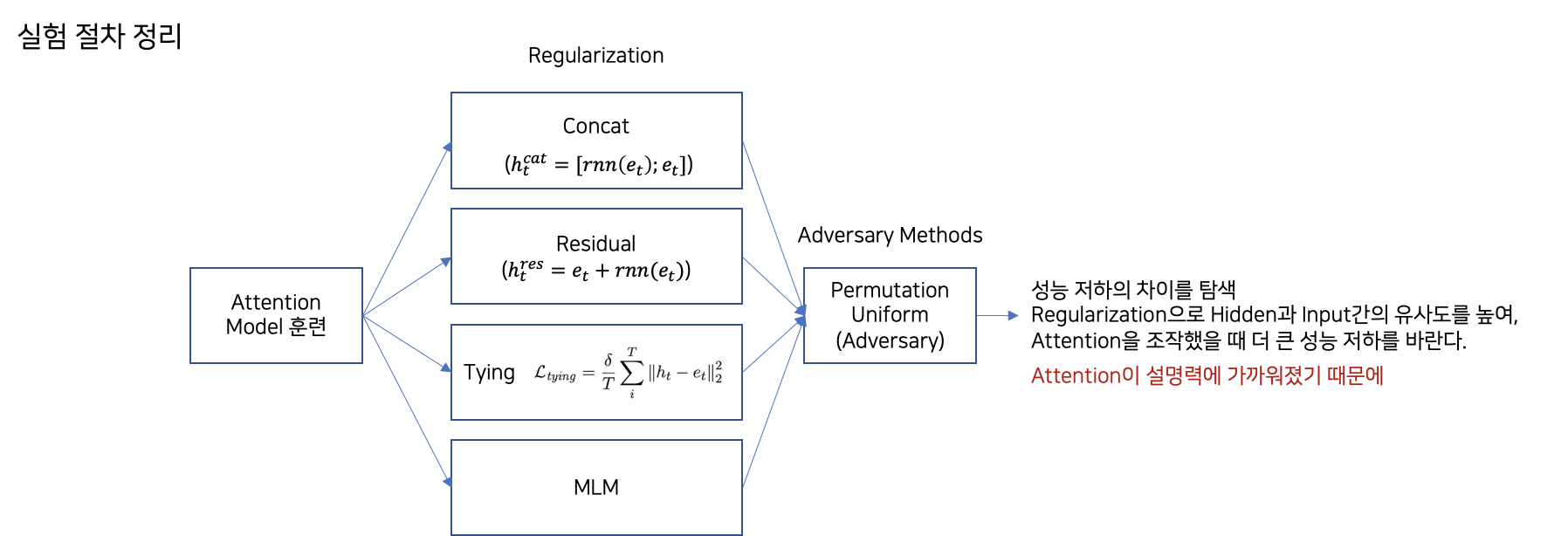
정규화를 통해 구성한 Input과 Hidden Representation에 대하여 Attention is not Explanation에서 진행한 방식대로 Adversary Attention을 구했을 때, 이전에 보였던 같은 결과에 대한 다른 Attention이 나타나는 것의 반대 결과를 보고 싶은 것입니다. 즉, 해당 절차를 통해 Attention이 설명력에 가까워졌기 때문에 Attention의 고유성을 침해했을 때, 결과가 달라지는 것을 원하는 것입니다.
일련의 결과들을 살펴보겠습니다.
Experiments Results
- Attention is Fragile
- 정규화를 적용하고 Attention에 Perturbation을 가했을 때 성능 저하 수준이 더 크게 나타난다.
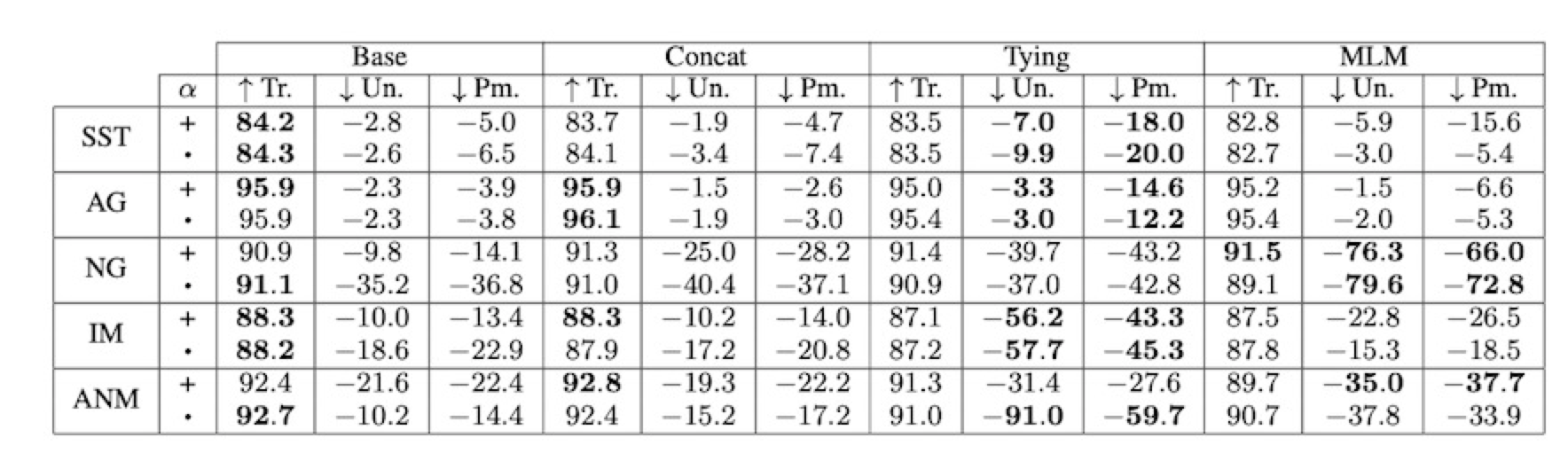
-
Adversarial Attention Distributions are Harder to Find
- MLM Regularized Model에 대하여 Model Based Adversarial을 통해 Attention을 만들었을 때, Base Model / MLM Model 을 비교했을 때, MLM Model이 더 높은 JSD를 위하여 더 큰 TVD 발생
추가 실험으로는
Attention이 각 토큰의 중요도를 나타내는 것이라면, 가장 중요한 하나의 토큰만 입력으로 사용했을 때의 결과 확률이 달라질까?
에 대한 질문에 답을 해보고 싶었습니다.
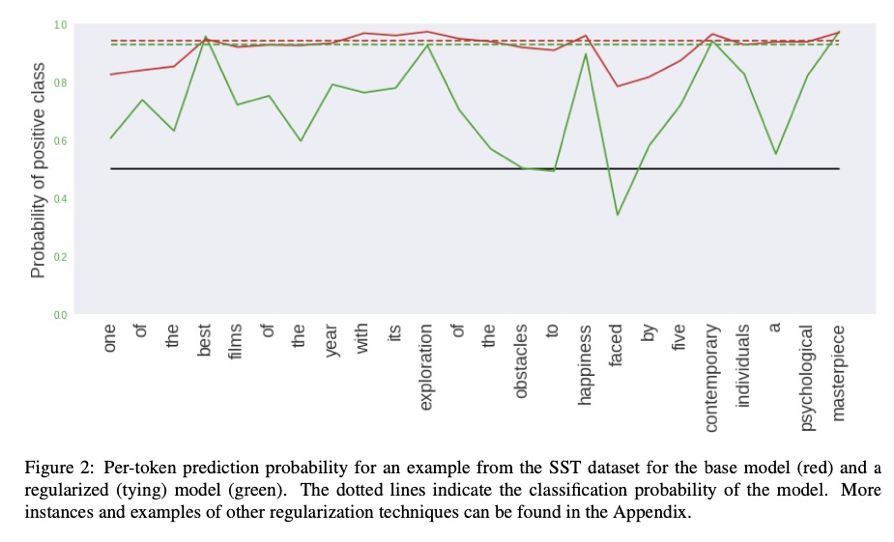
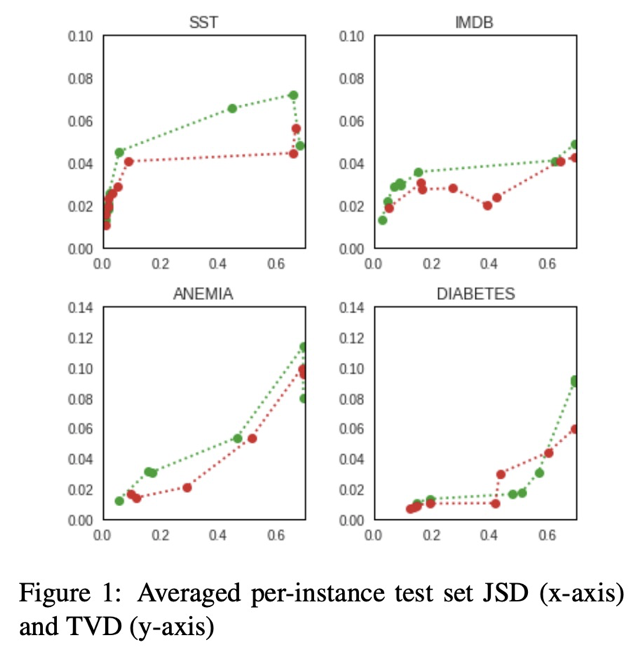
위의 그림에서 빨간 색은 기존의 모델, 초록색 선은 정규화 모델을 의미하는데, 모델 내에 토큰 하나씩만을 입력으로 넣었을 때의 성능을 볼 수 있습니다. 빨간색 선은 모든 입력 값에 대한 결과가 유사한데에 반해 초록색 선은 개별 입력 값에 대한 성능 차이가 명확하게 나타나 주요 토큰에 대한 가중치를 표현할 수 있다고 할 수 있습니다.
연구 의의
본 연구의 의의를 정리해보면 다음과 같습니다.
- Attention이 설명력으로서의 역할을 못하는 이유는 Input과 Hidden representation의 괴리로서 나타난다.
- 따라서, Input과 Hidden Representation을 유사하게 만들어주는 Regularization을 적
- Concat, Residual, Tying, MLM
- 실험 결과, Regularization을 거친 모델들은 같은 결과를 내는 Permutated Attention을 만들기 어려웠다. 즉, Input과 Hidden이 유사해짐으로써 Attention이 설명력으로서의 의미가 강해진 것이다.
Is Attention Interpretable?
본 논문 역시 Attention != Explanation 진영의 논문입니다. 저희는 지금껏 Attention이 모델의 결과에 대한 각 입력 값의 중요도를 말해준다는 것을 진리처럼 알고 있었습니다.
본 논문은 다음과 같은 목적을 갖고 있으며, Attention is not Explanation이 회장님이라면 본 논문은 사장님 정도의 포지션을 갖고 있습니다.
- 특정 Output을 내는 Attention에서 가장 높은 값을 제외하면 Output이 뒤바뀔까? (Decision Flip)
- Attention의 형태 변화의 관점보다는 성능 변화의 관점으로 살펴봄
실험 구조
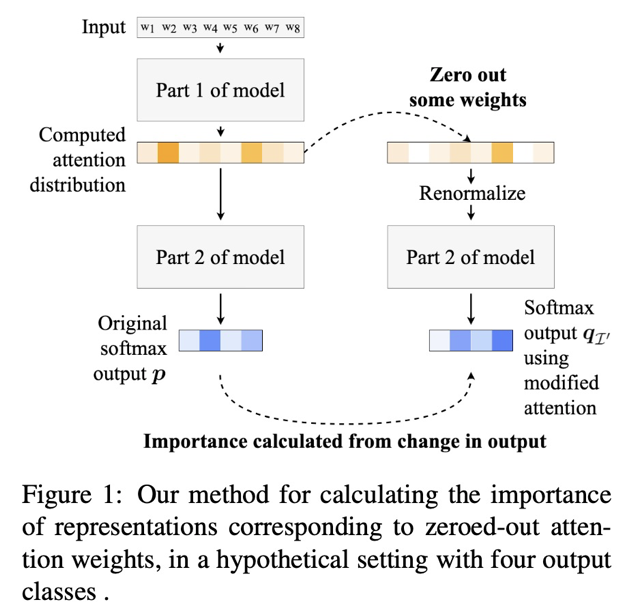
-
Input에 대하여 Attention Distribution을 계산하고, Original Softmax Output을 구한다.
-
몇몇의 Attention Weights를 제거한 뒤 Renormalize를 한다.
-
몇 개의 Attention Weights를 제거해야 Output이 뒤바뀌는 지 살펴본다.
소수의 Attention Weights를 제거했을 때 (0으로 만들었을 때), 결과가 바뀐다면 해당 Attention이 중요한 요소에 매핑을 잘 했다고 판단하는 것입니다.
실험 환경은 Binary Classification Task를 메인 과제로 설정했으며, Encoder들 역시 다양하게 설정하였습니다. RNN, CNN, No Encoder라는 이름의 세 가지 방식을 제안하며, 순서대로 입력 값들의 Contextualization의 차이가 있다고 가정하기 때문에, 이를 조절해가며 영향력을 파악해보고자 하는 것입니다.
실험 결과
- 실험 1 (Single Attention Weight) (Attention 분포의 가장 큰 i 번째 element 삭제) vs (Random 하게 삭제)
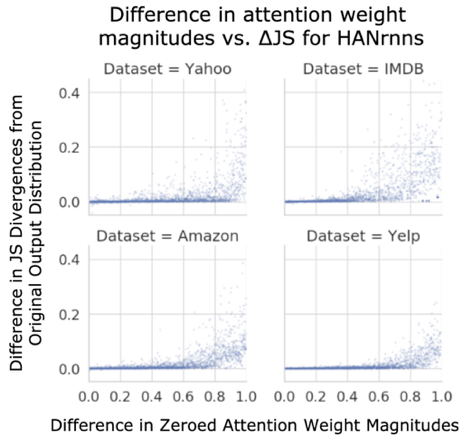
모든 Encoder에 대하여 Attention을 높은 값 순서대로 나열한 뒤, 하나씩 삭제했을 때 Output Distribution이 어떻게 변하는 지를 살펴보았습니다. 이 때, y축이 Output 분포의 차이를 나타내는 JSD 그리고 x축이 삭제한 Attention의 가중치를 나타내는 것입니다. 위의 그림을 살펴보게 되면 0~1까지의 Attention을 받는 대상에 대하여 특정 토큰을 삭제했을 때 JSD가 0에 매우 가까운 것을 볼 수 있습니다. 즉, Attention이 낮든 높든 해당 요소를 삭제했을 때 결과에 큰 영향을 주지 못한다는 뜻입니다.
-
실험 2 (Sets of Attention Weights)
이전 실험은 하나의 Attention을 지운 뒤, 결과 분포의 차이를 살펴보았습니다.
두 번째 실험에서는 Attention을 높은 순서대로 하나씩 지워나갈 때, 결과가 바뀌게 되는 시점을 파악하였습니다.
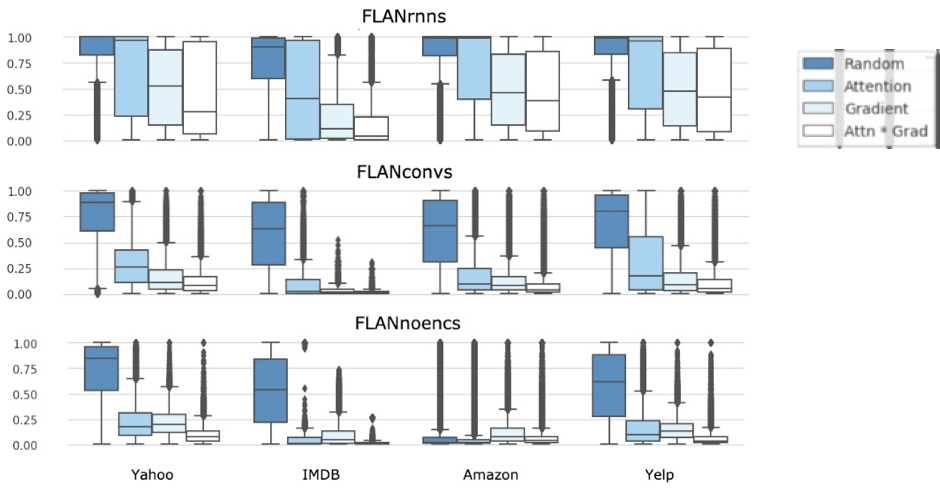
FLAN으로 시작하는 것은 각 인코더인 RNN, CNN, NoEnc를 나타내는 것이며, 데이터셋과 인코더에 따라서 현재 그림의 패턴이 모두 유사한 것을 볼 수 있습니다. 우측 Legends에서 볼 수 있듯, 진한 파란색이 Attention을 Random 분포로 나타내 입력 값들을 정렬한 경우이고 나머지들이 Attention 가중치 순서대로 정렬한 것입니다. Gradient는 해당 입력 값에 대한 미분 값이 큰 순서대로 정렬한 것이며, Attn * Grad는 이 둘의 수치를 곱해서 정렬한 것입니다.
결과적으로 살펴보게 되면
- RNN에서 Random보다 다른 조건에서, 결과 변화를 볼 수 있는 제거 비율이 유사함
- Contextualization이 줄어드는 Conv나 NoEnc에서 그 비율이 급감함
즉, Attention의 핵심 의미인 ‘중요한 요소에 집중한다’라는 의미가 유지되려면, 중요한 값들부터 삭제했을 때 빠르게 결과의 변화가 나타나야 하는데 Random으로 삭제한 경우와 유사한 비율로 삭제해야 결과가 변하는 것을 볼 수 있습니다. 이는 Attention이 중요 단어에 대한 가중치를 표현하지 못한다는 것을 나타내며 RNN에서 해당 현상이 가장 두각적으로 나타납니다. 이에 반해 각 입력 값이 지나치게 Mingle되는 Contextualization이 덜 나타나는 인코더에서는 해당 현상이 적게 나타납니다.