CS224W 8번째 강의 정리를 정리해보았습니다. 강의에서 사용된 이미지 전체는 CS224W 수업 자료에서 가져왔음을 미리 밝히는 바입니다.
강의 Link: Graph Representation Learning
강의 Slide: CS224W: Fall 2019
Intruduction
Basics of Deep Learning for Graphs
그래프를 Neural Network 연산 안에서 활용하기 위한 방법은 매우 간단합니다.
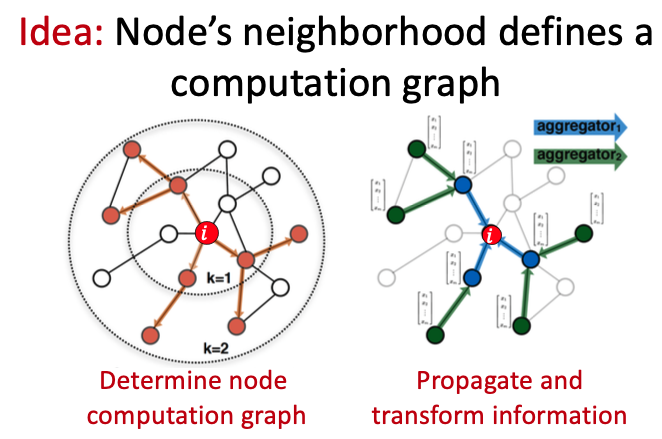
위와 같은 Graph에서 Node $i$의 Feature를 계산해내는 과정은 다음과 같습니다.
- Node $i$와 그 이웃들은 Computation Graph의 관계를 갖는다.
- Computation Graph를 따라 Propagate하며 Node 정보들을 Transform.
해당 과정을 통해 Graph의 구조 정보와 이웃들의 노드 정보로 중심 노드를 구축하는 것이 가능하며, 결국 중심노드와 이웃노드들 간의 Computation Graph를 구축하는 것은 Neighbor들을 Aggregate하는 것입니다.
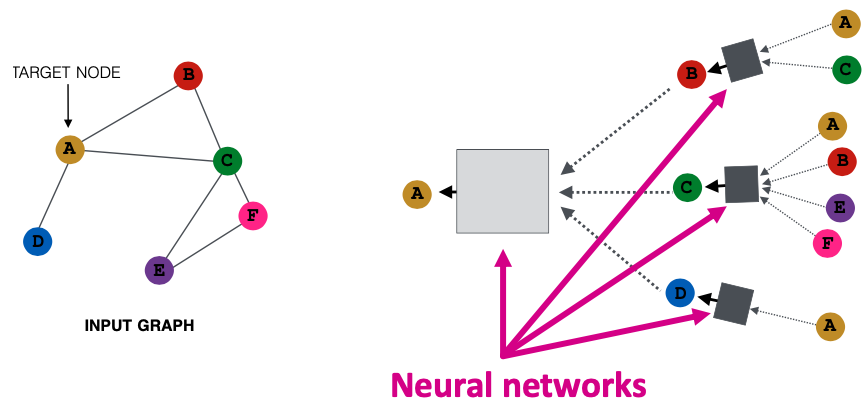
이는 다음과 같이 Input Graph가 있고, A 노드에 대한 Embedding을 구축한다면 A의 이웃 세 개에 대한 Embedding을, 해당 세 개의 노드들에 대한 이웃들로 구축하여 만들고 총 취합하여 생성합니다. 취합의 과정을 하나의 Neural Network라고 볼 때, 우측 그림에서 2개의 Layer를 쌓은 Neural Network라고 간주할 수 있습니다.
주의사항
- Aggregation은 노드가 어떤 순서로 들어가든 같은 Output을 내뱉는 Order Invariant이어야 합니다. 따라서, 평균이나 최대값 같은 연산을 사용해야 합니다.
- Neural Network는 4-5개 이상 쌓지 않는 것을 추천합니다. 하나의 Layer는 1-hop에 해당하는 연산인데, 이전 강의에서 살펴봤었던 MSN Network를 생각해보면 Diameter가 6이었습니다. 그렇다면 6-hop이상 넘어가는 연산은 그래프 전체를 살펴보게 되는 것이므로, 이웃의 정보를 반영한다는 의미보다는 그래프 전체를 순회한다는 느낌을 갖기에 Local 정보를 반영할 수 없습니다.
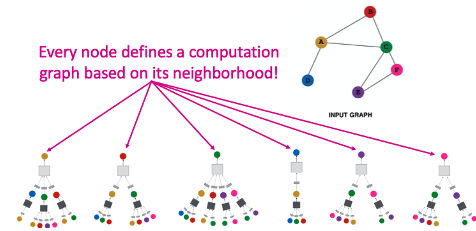
따라서 위의 그림과 같이 각각의 개별 색깔의 노드를 표현하기 위하여 해당 노드들의 이웃을 Aggregate하는 Neural Network를 구성하는 것을 볼 수 있습니다. 그리고 신기하지만 당연하게도, 각 노드를 구성하는 Neural Network의 꼴은 다른데, 각자 이웃의 개수 및 연결 노드가 차이 나기 때문입니다.
그렇다면 지속적으로 언급되던 Neural Network는 어떻게 구성하게 될까요? 위에서 취합의 과정을 Neural Network라고 말씀드렸지만 사실 취합 후 Neural Network를 거쳐 중심 노드의 Embedding을 구축하는 것입니다. 이는 아래와 같은 구조를 갖게 되는 것입니다.
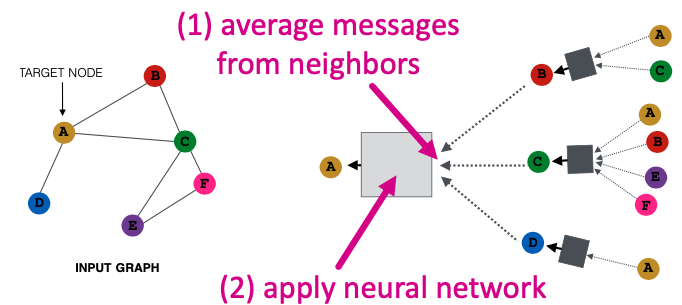
해당 과정을 수식으로 보면 다음과 같습니다. 본 강의에서 이미지들을 많이 가져오고 있는데 강의의 PPT가 너무 잘 만들어져 사용을 멈출 수가 없습니다…
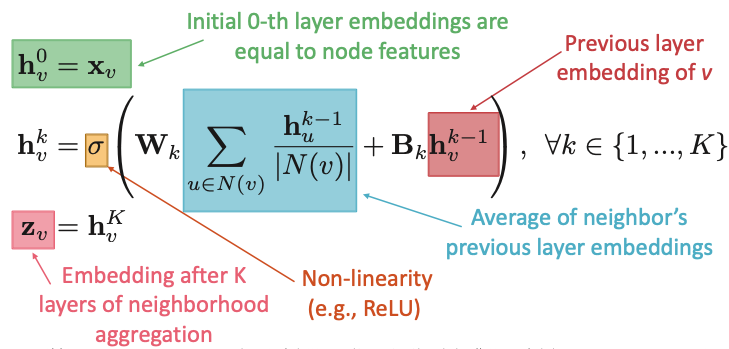
수식을 살펴보면,
- $h_v^k$: $v$노드의 $k$번째 Layer에서의 hidden state이다. 따라서 $k$가 0일 경우, Initial State로서 단순히 노드들의 Feature라고 할 수 있다.
- $W_k$: Transformation Matrix (Aggregation): $v$노드의 이웃 노드 $u$들을 모두 더하여 개수로 나눈 값에 대하여 Transform하는 가중치이다.
- $B_k$: Transformation Matrix (Self Transformation): $v$노드 자체의 Feature / Embedding을 Transform하는 가중치
- $\sigma$: Activation Function
- $z_v$: $K$ 번의 Layer를 거치고 난 뒤의 $v$노드 Embedding
위의 식에서는 $W, B$의 두 가지 가중치 행렬이 존재하며, 이 둘은 각기 이웃 노드와 중심 노드에 대한 계산 행렬입니다. 행렬의 역할이 명확하게 구분되어 있으므로, 그 둘의 대소관계를 통하여 하나의 Embedding을 구성함에 있어 중심 노드의 값을 더 반영하는지, 이웃 노드의 값을 더 반영하는지 파악할 수 있습니다.
Supervised Training
GNN을 활용하여 Supervised Training을 진행할 때의 Objective Function은 아래와 같이 Cross Entropy Loss 꼴로 구성합니다.
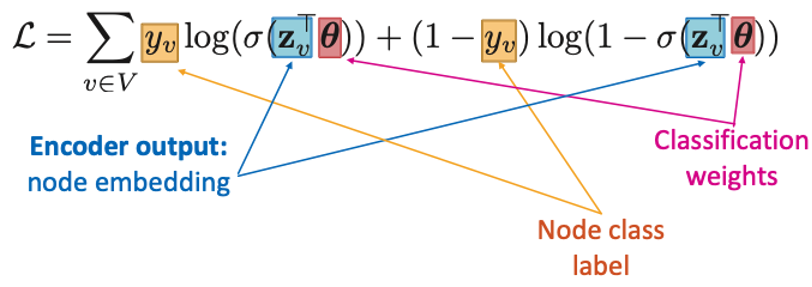
이를 통해 훈련 과정은
-
Neighborhod Aggregation Function 구성 = Neural Network Layer
-
Embedding에 대한 Loss Function 구성
-
배치별 노드에 대하여 훈련
-
이를 통해 훈련에서 사용하지 않았던 노드들, 즉 새로운 노드들도 Embedding 가능
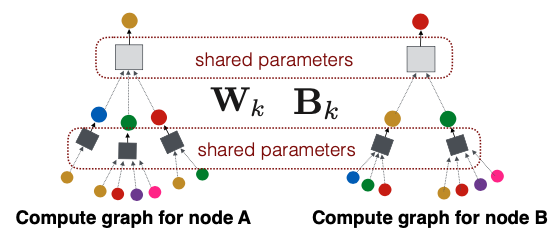
GraphSAGE
(GraphSAGE의 저자는 슬라이드에서는 Hamilton et al.이라고 적혀있지만 사실 강의자인 Jure 형님이 공저자로 들어가 있습니다. 왜 Jure 형님에 대한 호칭이 형님으로 격상되었냐면, 원래 러시아인 Jure 형님의 발음이 매우 이색적이라 듣기가 조금 이상했지만, Co-Instructor인 Michele에 비해선 엄청나게 명확한 발음이라고 생각이 들기 때문입니다. Michele은 말의 일부가 거의 모자이크 처리되는 느낌인데, Jure 형님은 발음이 완벽하지는 않아도 완벽한 딕션의 소유자라서 너무 좋습니다…)
위의 방식은 이웃 노드의 정보를 Aggregate하여 중심 노드의 Embedding을 구성하는 가장 기본적인 방식을 살펴 보았습니다. 따라서 이후의 해당 기법들의 발전 방향은 ‘Aggregate’의 방식을 좀 더 효율적이고 확실한 의미를 반영할 수 있는 방식으로 나아갔는데, 그 중 하나가 GraphSAGE입니다.
저희는 기본적인 방식에서 이웃 노드에 대한 Aggregation과 중심 노드에 대한 Transform이 ‘더해지는’ 방식으로 다음 단계의 Embedding을 구축하는 것을 살펴보았습니다.
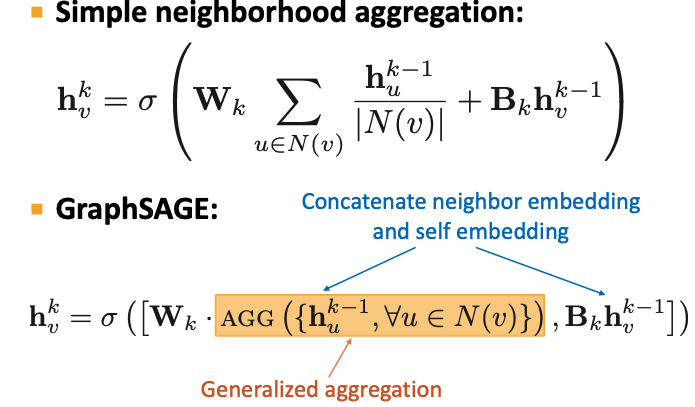
하지만 GraphSAGE의 SAGE부분이 Sample and Aggregate로서 강의에서는 Sample에 대한 이야기는 하지 않지만, Aggregate에 대한 방식에 대하여 더 발전시켰기에 다음과 같은 이름을 지었습니다. 즉 GraphSAGE에서는 이웃들에 대한 Aggregation과 중심 노드를 Concat한 다음 Activation Function에 보내는 과정을 거치고 있습니다.
그렇다면 Aggregate를 하는 방식은 어떻게 될까요? 강의 및 논문에서는 세 가지를 제안하고 있습니다. 이에는 Mean / Pool / LSTM이 존재하며, 이는 다른 포스트에서 더 자세하게 다루겠습니다.