Semtiment analysis using support vector machines with diverse information sources
본 논문을 요약하고 정리한 이유, 그리고 진행과정을 먼저 설명하고자 한다.
-
Paperswithcode에 따르면 SVM 논문들이 활용한 Task 중 가장 많이 사용된 것이 Sentiment Analysis (하지만 이는 결국 딥러닝 이전의 논문들이 많아서 발생한 결과였다.)
-
이에 과거에는 Sentiment Analysis를 SVM을 통해 어떻게 진행했는 지 살펴보고자 함
-
논문을 모두 정리하고 요약을 마치고, 구현을 해볼려던 찰나, 실험의 대부분의 요소(데이터 셋 출처)가 Deprecated 됨을 발견
-
이에 다른 두 논문을 조사하여 Sentiment Analysis를 진행 (Word2Vec & Multiple Kernel SVM)
Introduction
감성분석이란 말 그대로 글의 ‘감성’을 파악하는 것이다. 사전적 뜻을 보면
“이성(理性)에 대응되는 개념으로, 외계의 대상을 오관(五官)으로 감각하고 지각하여 표상을 형성하는 인간의 인식 능력.”으로 나타나기는 하나, 감성분석에서 의미하는 감성은, ‘감정’과 유사하다.
유사하지만 동일하지는 않은 개념이기에 차이를 정리해보겠다.

감성: 좋고 싫음, 긍정 부정과 같이 Binary 값으로 표현하거나 이에 ‘중립’값을 더해 (-1, 0, 1)의 값으로 나타낸다. (1차적 자극) 감정: ‘슬픔’, ‘행복’, ‘사랑’, ‘후회’ 등 구체적인 마음 (1차적 자극을 수용하여 해석한 2차적 자극)
하지만 아쉽게도, 적어도 한국에서 감성분석을 얘기할 때, 감성과 감정을 혼용하곤한다. 이 둘은 다른 개념이기에 영어로 옮길 때도, 감성분석은 ‘Sentiment Analysis’, 그리고 감정 분석은 ‘Emotion Analysis’로 표현된다. 따라서 이 둘을 명확하게 구분해야 한다.
그렇다면 문장 또는 글의 감성분석은 어떻게 진행될까?
초기 시절에는 문장을 구성하고 있는 단어들의 감성을 모아서 문장 전체의 감성으로 표현했다. 좋은 감성을 담은 단어들이 한 문장에 많으면 그 문장은 긍정적인 문장이 되는 것이다. 이에 감성사전이라는 것을 따로 구축해, 문장 내 포함된 단어들의 감성 점수를 내고 총합하는 방법으로 진행된다 (ex. KnuSentiLex)
“본 헤어드라이기는 바람이 매우 잘 나오고, 사용했을 때 기분이 너무 좋아서 사랑에 빠질 것 같다.”
해당 상품평은 확실히 문장 내에 부정적인 감성 갖는 단어는 없고 오로지 긍정적인 감성을 담은 단어만 있기에 긍정 감성 문장이라고 판단할 수 있다. 하지만 이렇게 단어 또는 n-gram의 감성들의 총합으로 문장의 감성을 판단하는 것은 매우 큰 단점이 있다. 다음의 예시를 봐보자.
“샐러드는 너무 맛있고 몸이 건강해져서 행복할 때도 있지만, 사실 이것만 먹고 지내다가는 내 정신이 무너질 것 같다.”
‘맛있고’, ‘건강’, ‘행복’과 같은 긍정 감성을 담은 단어들이 문장내에 3번 등장하고, ‘정신이 무너진다’ 와 같은 부정 감성을 담은 부분이 하나만 존재하지만, 전체 문장을 구성하는 감성은 부정이다. 긍정으로 이어지다가 마지막에 반전을 두어 전체 문장의 감성을 180도 바꾸어 버리기 때문이다.
Pang et al.(2002)는 하나의 문장의 감성이 단어들의 감성과 달라지는 대표적인 이유가 “Thwarted Expectations”, 즉 기대가 와르르 무너졌을 때 나타난다고 한다. 예를 들어 음반에 대한 평을 살펴보자.
“음반이 도착했을 때, 커버가 너무 이쁘고 같이 온 사은품도 너무 좋아서 기분이 좋아졌다가 노래를 듣고 토하는 줄 알았넹” (논문 예시 각색)
“이들은 기존과 아주 다르고, 처절하게 패배했고 절망적인 밴드이다. 하지만 다른 밴드가 할 수 없는 것을 해내었다.” (논문 예시 각색)
확실히 기대를 연속적으로 하다가 이를 저버리는 특성이 나타나면 전체 문장의 감성이 변하는 것을 볼 수 있다.
따라서, 문장에 대하여 있는 그대로, 단어 또는 n-gram에 기반한 감성분석을 시행하면 반드시 오분류를 할 수 있게 된다. 이에 본 논문에서는 문장에서 최대한 다양한 정보들을 추출하여 Feature를 뽑아내고 그것을 활용해 SVM Classification을 진행하고자 한다.
수많은 분류 기법 중에서 왜 SVM을 사용했는 지는 아직 잘 모르겠다. 논문에서 거론하기로는 SVM이 문장 내외에서 모은 정보를 하나로 규합해 만든 좋은 Feature를 잘 활용할 수 있는 기법이라고는 하나, 크게 공감은 안된다.
Methods
3.1 Semantic Orientation with PMI
Semantic Orientation (SO)는 단어 또는 문장의 긍정 / 부정 감성의 실수 척도라고 할 수 있다. 단어 자체에 방향을 뜻하는 Orientation이 포함되어 있으니 ‘감성이 향하는 방향’이라고 생각해도 될 듯 하다. SO를 산출하기 위해서는, 글에서 온전한 ‘문장’을 추출해야 한다. 단어 하나, 또는 온전한 문장이 아니라면 감성 추출의 대상이 될 수 없기에 미리 필터링을 하여 필요 없는 부분을 글에서 삭제하는 것이 작업에 큰 도움이 될 것이다. 그리고 해당되는 온전한 문장들을 SO라는 ‘Value’를 담고 있다고 해서, ‘Value Phrases’라고 부를 것이다. Value Phrase는 Turney(2002)가 제안한 방식을 사용할 것이며, Figure 1에서 제시하는 패턴을 만족하는 문장들을 선택한다.
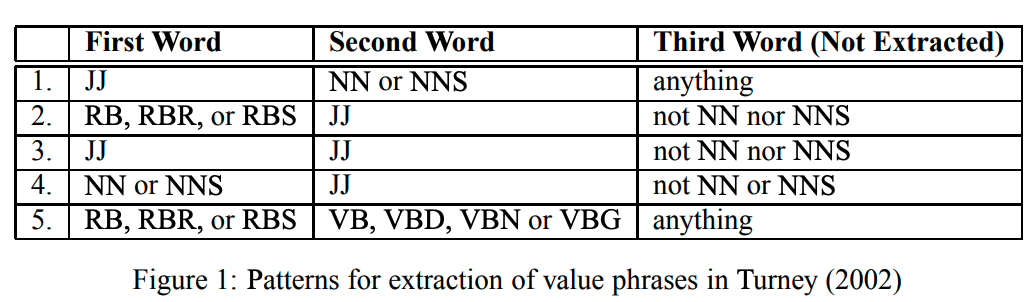
전체 글의 Value Phrases을 추출한 뒤, Sentiment Analysis의 Label이 될 SO를 추출하는 방식에서 해당 논문의 제목이 왜 ‘with diverse information sources’ 가 포함되어 있는지 알 수 있다. 문장의 단어를 순회하면서, 단어마다 “excellent”와 “poor”의 PMI 값을 추출하는데, 이 때 사용하는 기준점이 “AltaVista Advanced Search engine”(Deprecated)이며, 단어가 “excellent”와 10개의 단어 내에서 존재할 때 co-occurrence를 나타낸다.
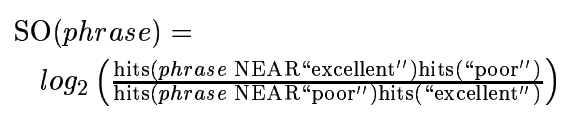
SO점수가 양수이면 긍정을 나타내고, 음수이면 부정을 나타내며, 0이면 중립을 나타내는 감성 점수를 얻게 되는 것이다.
처음에는 본 점수를 Label로서 활용하는 듯 하였다. 하지만 데이터셋에 이미 Label이 포함되어 있을테니 이는 필요가 없을 것이며, 따라서 이도 Feature Value로서 활용되게 된다. 즉 본 논문에서 사용하는 2가지의 Feature Value 중 첫번째임을 생각해야 한다.
3.2 Osgood semantic differentiation with WordNet
다음 Feature로서 활용할 데이터는, 또다른 “Diverse Information Sources”인 WordNet을 활용하는 것이다.
WordNet은 영어의 의미 어휘목록으로서, 어휘 목록 사이의 다양한 의미 관계를 기록해 놓은 시스템이다. 해당 WordNet을 통해 단어들의 세 가지 값을 추출해내는데 이는 다음과 같다.
- Potency (Strong or Weak) - POT
- Activity (Active or Passive) - ACT
- Evaluative (Good or Bad) - EVA
문장 단어들의 해당 값들을 모두 추출한 뒤, 각기 평균을 내게 되면 3차원의 벡터로서 SVM에 Input으로 포함되는 값이 나타내게 된다. 또한 이런 감성을 담고 있는 대상은 “Notebook”, “Food”와 같은 명사가 아니다. 명사 그 자체로는 감성이 담겨져 있을 수가 없고, 그것을 표현하는 형용사에 감성이 담겨있기에 위의 세 점수를 구하는 대상은 형용사만으로 한다.
3.3 Topic proximity and syntatic-relation features
감성은 보통 대상이 있어야 존재할 수 있다. ‘싫다’라는 감성이 피어오르기 위해선 결국 ‘사람’/’상황’/’물건’과 같은 대상이 있어야 존재할 수 있는 것이다. 본 논문에서는 전체 글에서 감성을 담고 있는 대상이 단일하지 않고, 복수 개가 존재할 수 있다는 상황을 제시한다. 예를 들어
- 책을 평가할 때, 책의 내용을 평가하는 동시에 저자를 평가할 수도 있다.
- 상품을 평가할 때, 상품 자체를 평가하는 동시에 제조사를 평가할 수도 있다.
따라서 문장의 감성을 계산할 때, 평가 대상(Topic)이 두 개 이상 있을 경우, 해당 감성들을 어떻게 규합할 지 생각을 해야한다. 이에 본 논문의 저자들을 직접 Annotation을 실시해서, 문서의 Topic들을 일일이 나누어서 Sentiment Analysis를 더 효율적으로 할 수 있는 방법을 제시한다.
3.4 Support Vector Machines
이 논문을 선택하고 구현하기로 한 이유는 다음과 같다.
- SVM
SVM과 관련되고, 본인이 관심이 있었던 주제인 Sentiment Analysis에 어떻게 적용이 되는 지 살펴보고 싶었다. 또한 Paperswithcode에 들어가서 SVM에 어울리는 논문을 살펴보던 중, 검색어를 SVM으로 지정했더니 사용한 Task의 비율에서 Sentiment Analysis가 많은 자리를 차지하였다. 물론 성능 랭킹에서 SVM을 찾아볼 수는 없지만, 높은 비율에 놀랐다.
이에 “SVM의 어떤 특징이 Sentiment Analysis에서 두각을 보이나?”라는 의문이 나타났다. 이에 검색 및 연구실 분들께 질문을 한 결과, 여러 Classification 기법 중 감성 분석에서 SVM이 많이 사용된 이유는 딱히 없으며, 딥러닝이 효과를 보이기 전까지 Binary Classification에서 많이 사용되었기 때문이라고 한다. 본 논문도 2004년 논문이고, 사용하는 방법 중에서는 아예 Deprecated된 사이트도 있으며, WordNet을 사용하는 자체가 구식인 것을 보아 단순히 과거로부터 축적된 빈도로 인해 오해했던 것 같다.
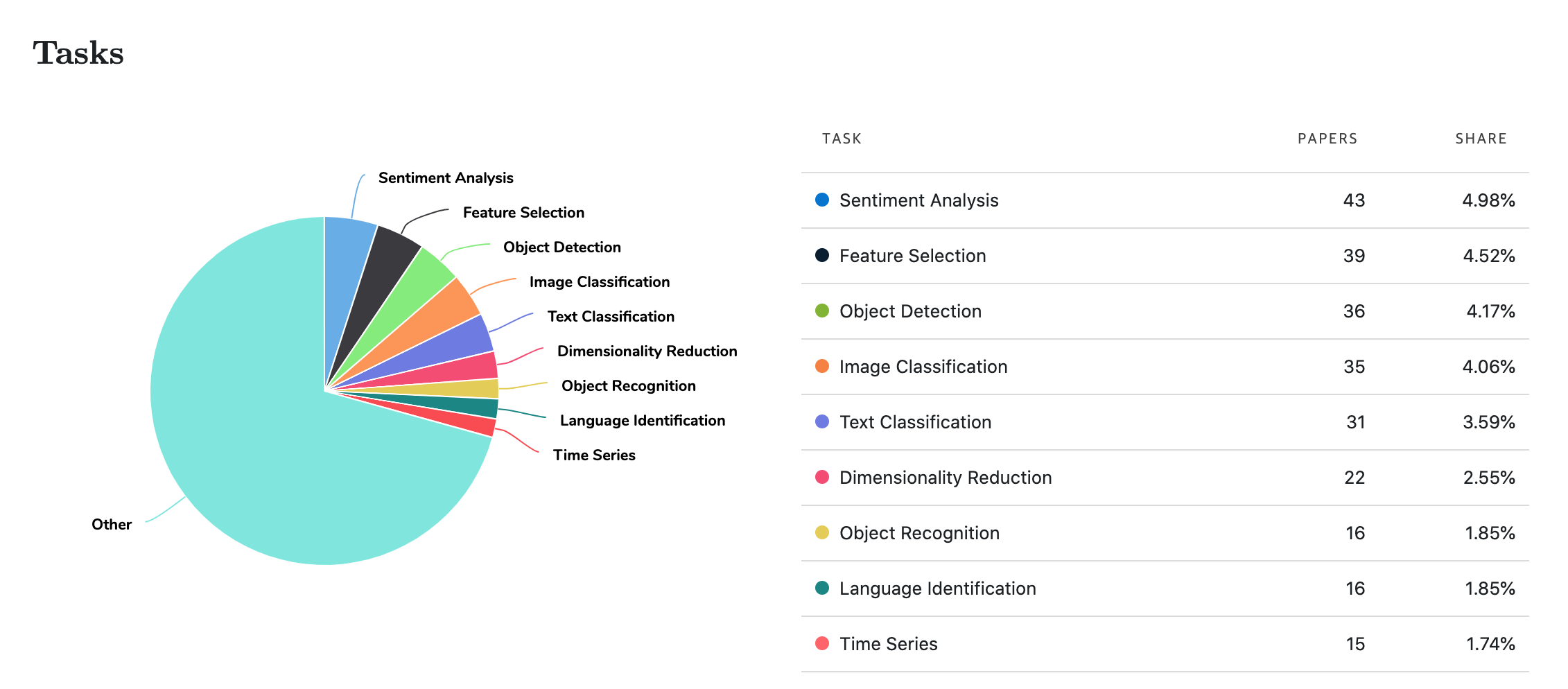
- Sentiment Analysis
즉, 감성 분석에서 SVM이 딱히 두각을 나타내는 성능을 보여준다고 하기는 어렵다. 그럼에도 본 논문을 선택한 이유는 하나의 기법을 공부함에 있어, History를 아는 것은 매우 중요하다고 생각하기 때문이다. 마치 LSA에서 LDA로 발전할 때 무엇을 수정하고 개선해나갔는지를 알면 과거와 현재의 특징을 더 명확하게 알 수 있는 것처럼 말이다. 이에 Text Data, 그리고 Sentiment Analysis에서 어떻게 SVM의 Input과 Label을 구성하는 지 알면, 감성분석과 SVM의 특징을 알고 개선의 방향을 판단할 수 있지 않을까 싶었으며, 고전의 방식을 많이 배울 수 있는 시간이었다.
4. Experiments
16년정도가 흐른 지금, 실험을 위해 사용된 Dataset의 위치는 대부분 사라졌다. 실험에 사용된 첫번째 데이터 셋인 Epinions.com Movie reviews는 쇼핑 사이트로 변해 있었다. 따라서 Dataset에 대한 설명은 제외하고 실험 방법에 대하여 초점을 맞춰보겠다.
위의 절차들을 따라, Feature와 Label을 계산할 수 있다.
- Feature: POT / ACT / EVA 의 문장별 평균 > 3차원 Feature
- Label: SO from Value Phrase
실험 절차는 Train-Test 데이터에 대하여 3/10-fold Cross Validation을 진행하였다. 그리고 문장들을 모두 길이에 대하여 성능의 향상을 보일 경우 Normalize를 하였다.
SVM을 진행할 때, Kernel Function도 함께 사용해보았지만, 딱히 큰 효과는 보지 못했기에 Linear Kernel 과 Polynomial Kernel만을 사용하였다 (d = 2)
5. Results
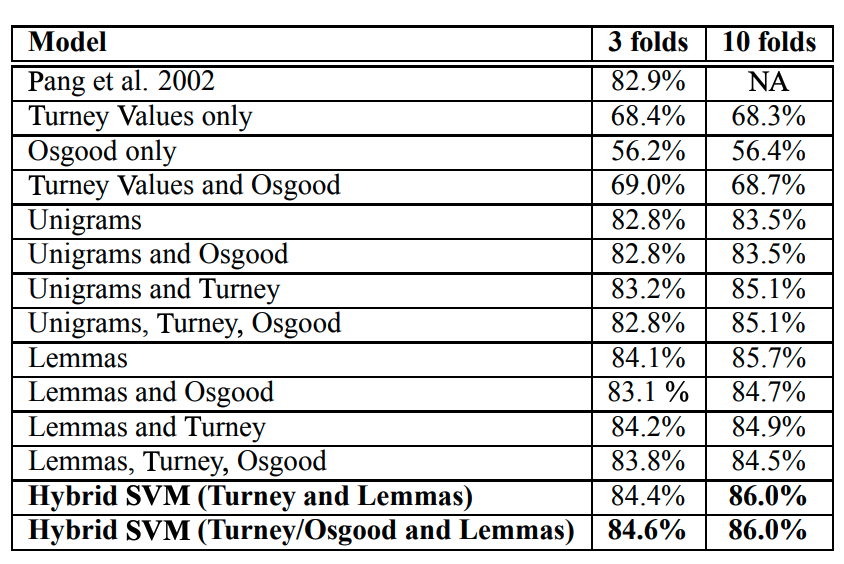
위의 표가 SVM의 3-folds와 10-folds의 결과이다. 여기서 짚고 넘어가야 할 점은, Unigrams과 Lemmas이다. Unigram은 ‘단어 하나’를 지칭하고, Lemmas는 어근을 찾는 Lemmatisation을 거친 단어들이다. 결과 표에서 해당 값들의 CV값이 나타나있지만, 이들을 어떻게 Input Feature로 만들었는지에 대한 설명은 존재하지 않아, 추가 검색을 해본 결과 CountVectorizor를 통해 빈도를 구해 적용하는 것으로 추측만이 가능했다.
결과표를 분석해보면, 본 논문에서 제시한 Turney Values(SO)와 Osgood(POT / ACT / EVA)만을 사용한 SVM은 성능이 비교적 좋지 않다. 결론적으로 생각해보면 그들이 갖고 있는 시선으로 만든 Feature가 생각보다 효과적이지 않다는 것이다. 그리고 저자들은 Baseline으로 활용한 Unigram과 Lemmas 값이 기존 결과보다 더 상회하는 것을 보여주며, Baseline에 자신들의 값을 추가하면 성능이 증가한다고 말하지만, 그것이 엄청나게 큰 폭은 아님을 알 수 있다.
또한 어떻게든 자신들의 새로운 값이 더 좋은 성능을 가져온다는 것을 나타내기 위하여 Hybrid SVM을 제시한다. Hybrid SVM이란 것을 정확하게 설명하지 않아서, 어떤 형태인지는 모르겠으나 ‘Combined’라는 단어로 표현하는 것으로 보아, Boosting같은 느낌이 약간 든다. 여기에서 Turney Value와 Osgood의 Input을 포함시켰을 때 성능이 증가한다고 했지만, 이 역시 단순히 설명변수의 증가로 인한 현상으로 보인다.
발전
결과적으로, 요약한 논문은 사실 큰 의의가 없게 되었다. 먼저 논문을 이해한 뒤 구현에 힘써보려고 했지만, 요약을 다 마친 후에 구현에 있어 Deprecated된 요소들이 많았기 때문이다. 이에 Sentiment Analysis와 SVM의 골격은 유지한 채 구현을 함에 있어, 다른 논문들을 참고하여 방식을 달리하여 구현을 진행하고자 한다.
참고 논문
-
Support Vector Machines and Word2Vec for Text Classification with Semantic Features - Joseph Lilleberg (2015)
해당 논문을 참고한 이유
원 논문에서 CountVectorizor만을 사용하지 않고, 다른 information sources를 첨가한 이유는 결국, 빈도만으로는 얻을 수 없는 정보인, Semantic한 Information 때문이다. 하지만, 보통 사람들, 또는 연구자들은 단일하거나, 간단하거나, Scalable한 알고리즘을 원하며 추가적인 데이터를 추구하지 않는다. 이런 조건들을 모두 만족하는 해결책은 Word Embedding 중 Word2Vec이 가장 기본적이면서 강력한 방법이라고 생각하기에 참고하였다.
특히 해당 논문에서는 TF-IDF를 가중치로서 활용하기도 하지만, 구현에서는 단어 Vector들의 단순 합을 Sentence Embedding으로 활용하고자 하며, 이를 SVM의 Input에 포함시키고자 한다.
-
Multiple Kernel Learning Algorithms - Mehmet Gonen, Ethem Alpaydm (2011)
해당 논문을 참고한 이유
원 논문에서 Hybrid SVM에 대하여 언급은 하지만 구체적인 꼴을 설명하지 않았다. 따라서 ‘Hybrid’라는 말과 유사한 ‘Multiple’을 대신 사용하고자 하며 이를 위해 Multiple Kernel Learning을 시도해보고자 했다. 이 때, 해당 논문에서 여러 Kernel Based Learning을 소개하지만, 가장 구현하기 쉬운, Kernel의 Summation을 통해 구현을 진행해보고자 한다.
구현
Sentiment Analysis 를 위해 많이 사용되는 Dataset 중 하나인 IMDB 리뷰 데이터로 구현을 진행하고자 한다.
데이터 셋 Input
단어에 대하여 이미 Tokenized가 되고 Vocab 사전의 Index로 대체되어 있는 꼴이다. 따라서 이를 Word2Vec을 통해 Vectorize하기 위해서는 Index가 아니라 단어 그 자체로 만들어줘야 하기 때문에 되돌려주는 작업을 거쳤다.
1 | |
IMDB Indexed Data

IMDB Original Tokens

데이터 셋 Output
0,1로 구성된 Binary Set으로서 각기 부정과 긍정을 나타낸다.
이후 Word2Vec에 전체 Corpus를 Input으로 넣고, window = 5, min_count = 5, 그리고 size=5를 Parameter로 설정하였다. Size를 더 크게 하면 Word2Vec의 차원이 더 커져 지나친 축소로 인한 정보 손실을 걱정할 필요는 없지만, 문장으로 이루어진 데이터 셋의 크기가 작은 편이 아니라 Size를 5로 설정했다.
그리고 Train / Test Dataset이 모두 25000이었지만, 이 역시 빠른 Computation이 안되어 Train 3천, Test 1천으로 나누어 실험하였다.
1 | |
위의 코드를 적용하게 되면,
- Tokenized된 단어들을 Word2Vec으로 전환한다.
- Word2Vec의 결과물은 각 단어마다 5차원의 Vector로 표현된 단어들로 나타나며, 이를 getAvgFeatureVec 함수를 통해 합하고 평균을 적용한다.
이로써, SVM을 통해 Classification을 하기 위한 Input Vector를 생성하였다. 따라서 이제 성능 평가를 진행할 것이며, 이 때 다음과 실험을 진행할 것이다.
-
Kernel을 변화시켜, Linear, Polynomial, RBF, Sigmoid Kernel을 통해 SVM을 진행
-
Multiple Kernel SVM을 진행하며, 이때 Polynomial Kernel과 RBF Kernel로 도출된 값을 Summation한 뒤, SVM의 Input으로 활용
실험 결과
- Kernel을 변화시켜, Linear, Polynomial, RBF, Sigmoid Kernel을 통해 SVM을 진행
실험 결과, 각 커널들의 결과는 다음과 같다.
1 | |
| Kernel | Accuracy |
|---|---|
| Linear | 0.55 |
| Polynomial | 0.61 |
| RBF | 0.64 |
| Sigmoid | 0.48 |
간단한 세팅과 Parameter Search 단계의 부재로 인하여 성능은 그렇게 좋지 않지만, Linear Kernel에서 Polynomial / RBF Kernel을 사용했을 때, 성능이 증가하는 것을 볼 수 있다. 하지만 Sigmoid Kernel은 오히려 성능을 악화시켰다.
- Multiple Kernel SVM을 진행하며, 이때 Polynomial Kernel과 RBF Kernel로 도출된 값을 Summation한 뒤, SVM의 Input으로 활용
Multiple Kernel SVM(MKV)의 구현은 상당히 까다로웠다. 원 논문에서 언급한 Hybrid SVM이 Boosting과 같이 각 알고리즘의 결과를 합친 것이라고 언급을 하였는데, Multiple Kernel SVM은 결과를 합치는 것이 아니라 Kernel Trick의 결과값을 합치는 것이기 때문이다. 따라서 기존에 SVM을 구현하기 위해 활용했던 sklearn에서는 제공하지 않기 때문에 다양한 소스를 찾아보았다. 그 결과, kernelmethods라는 패키지를 찾아냈고, 여기서는 Kernel 구현만을 제공한다.
물론, Sklearn에서도 sklearn.metrics.pairwise에 각종 커널들을 구현해 놓은 것이 있었다. 이에 처음에는 해당 패키지를 사용하여 MKV를 구현하고자 했으나, Train / Test 데이터를 구성하는 데에 있어 해결책을 못찾아 대안을 찾아낸 것이 kernelmethods였다.
kernelmethods
kernelmethod를 통해 MKV를 구현한 단계는 다음과 같다.
-
Linear, Polynomial, RBF, Sigmoid Kernel을 세팅하고 Pairwise KernelMatrix를 구성
1
2
3
4
5
6
7
8
9
10rbf = GaussianKernel() poly = PolyKernel() linear = LinearKernel() rbf_km = KernelMatrix(rbf) poly_km = KernelMatrix(poly) linear_km = KernelMatrix(linear) rbf_km.attach_to(w2v_sentences_train) poly_km.attach_to(w2v_sentences_train) -
KernelMatrix들끼리 Summation을 적용
1
combined_train = rbf_km.full + poly_km.full -
Summation 값을 SVM의 Input으로 사용
1
2svm = SVC(kernel = 'precomputed', verbose = True) svm.fit(combined_train, y_train[:3000]) -
Test Data에 대하여 적용하게 되면, 보통 Train보다 Test Data가 갯수가 적기 때문에, Pairwise KernelMatrix를 적용하게 되면, Test Data와 Train Data의 차원이 맞지 않아 Test에 사용할 수 없게 된다. 이 부분에서 sklearn을 사용할 수 없었던 이유인데, 정확한 원리는 모르겠지만 차원을 맞춰주는 기능이 있어 사용하였다.
1
2
3
4
5
6
7newrbf_km = KernelMatrix(rbf) newrbf_km.attach_to(sample_one=w2v_sentences_test, sample_two=w2v_sentences_train) newpoly_km = KernelMatrix(poly) newpoly_km.attach_to(sample_one=w2v_sentences_test, sample_two=w2v_sentences_train) combined_test = newrbf_km.full + newpoly_km.full -
Test Data를 통해 Accuracy 산출
1
2
3y_pred = svm.predict(combined_test) print('Accuracy: %.2f' % accuracy_score(y_test[:1000], y_pred)) # Accuracy: 0.6
아쉽게도 두 커널을 Summation하여 진행한 SVM이 RBF: 0.64, Polynomial: 0.61 보다 더 낮은 Accuracy를 기록하여, 성능이 더 저하된 것을 살펴볼 수 있었다. 이는 모델의 지나친 복잡성으로 인한 Overfitting으로 예상된다.